Universal-3 Pro vs Whisper: Hangi Konuşmadan Metne Modeli Daha İyi?

Universal-3 Pro vs Whisper: Hangi Konuşmadan Metne Modeli Daha İyi?
Otomatik Konuşma Tanıma (ASR) büyük bir paradigma değişimi geçirdi. Derin öğrenme tabanlı konuşma modellerinin gelişi, ham transkripsiyon doğruluğunu insan eşdeğerliğine her zamankinden daha fazla yaklaştırdı. Medya yerelleştirme araçları, video altyazı düzenleyicileri ve konuşma analizi paketleri geliştiren geliştiriciler için doğru arka uç modelini seçmek, kullanıcı deneyimini ve hesaplama maliyetlerini doğrudan etkileyen kritik bir karardır.
Bugün, Konuşmadan Metne alanının iki ağır topu OpenAI's Whisper (özellikle Whisper large-v3) ve AssemblyAI's Universal-3 Pro'dur. Whisper varsayılan açık kaynak favorisi haline gelirken, Universal-3 Pro kendisini lider kurumsal düzeyde yönetilen alternatif olarak kanıtlamıştır.
SRTGen olarak, profesyonel altyazı çalışma alanımız için her iki modeli de kapsamlı bir şekilde değerlendirdik. Bugün, kıyaslama analizimizi paylaşıyor, çalışma alanımızı neden nihayetinde AssemblyAI Universal-3 Pro etrafında inşa ettiğimizi açıklıyor ve her iki modelin doğruluk, halüsinasyonlar, biçimlendirme ve özellik setleri açısından nasıl karşılaştırıldığını inceliyoruz.
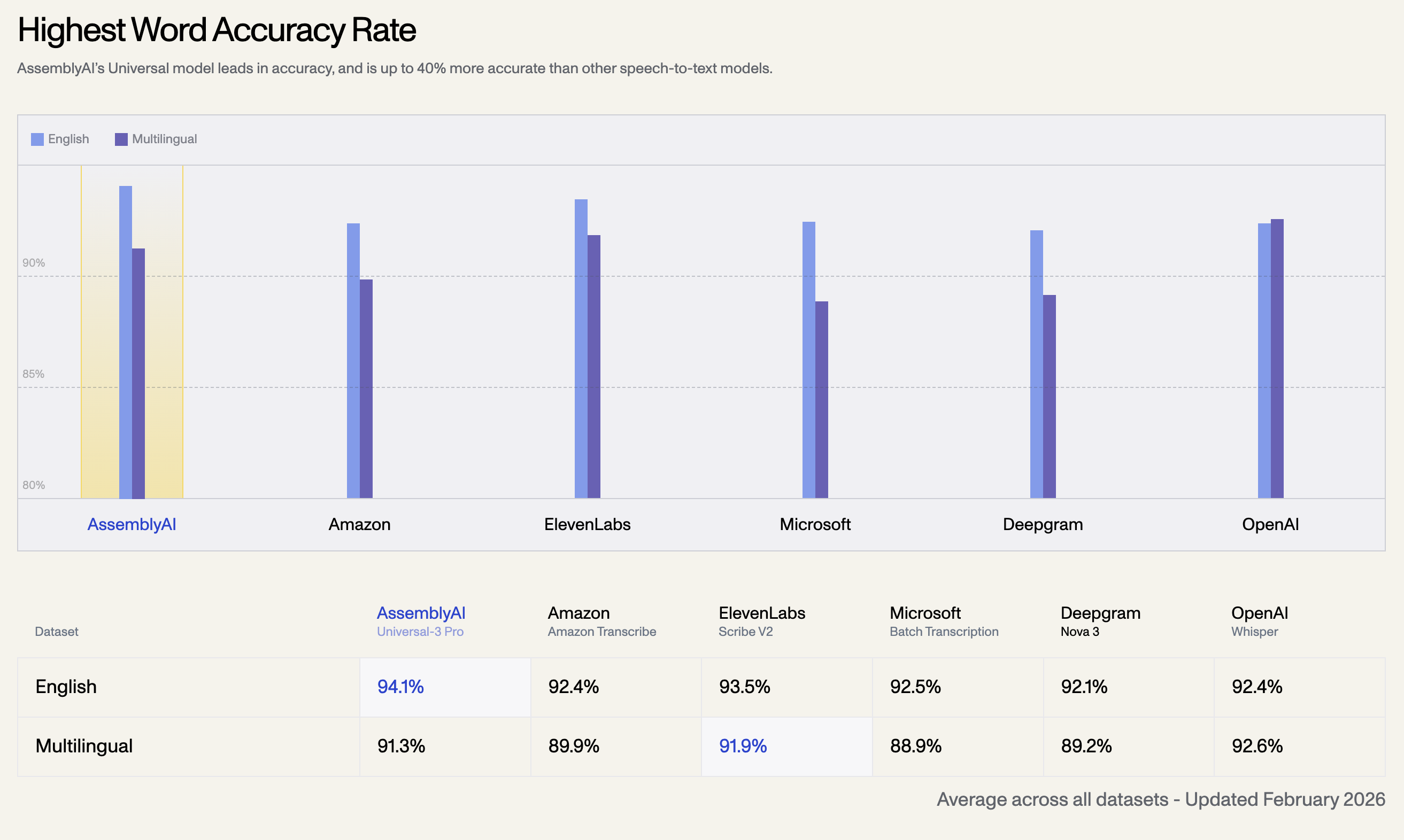
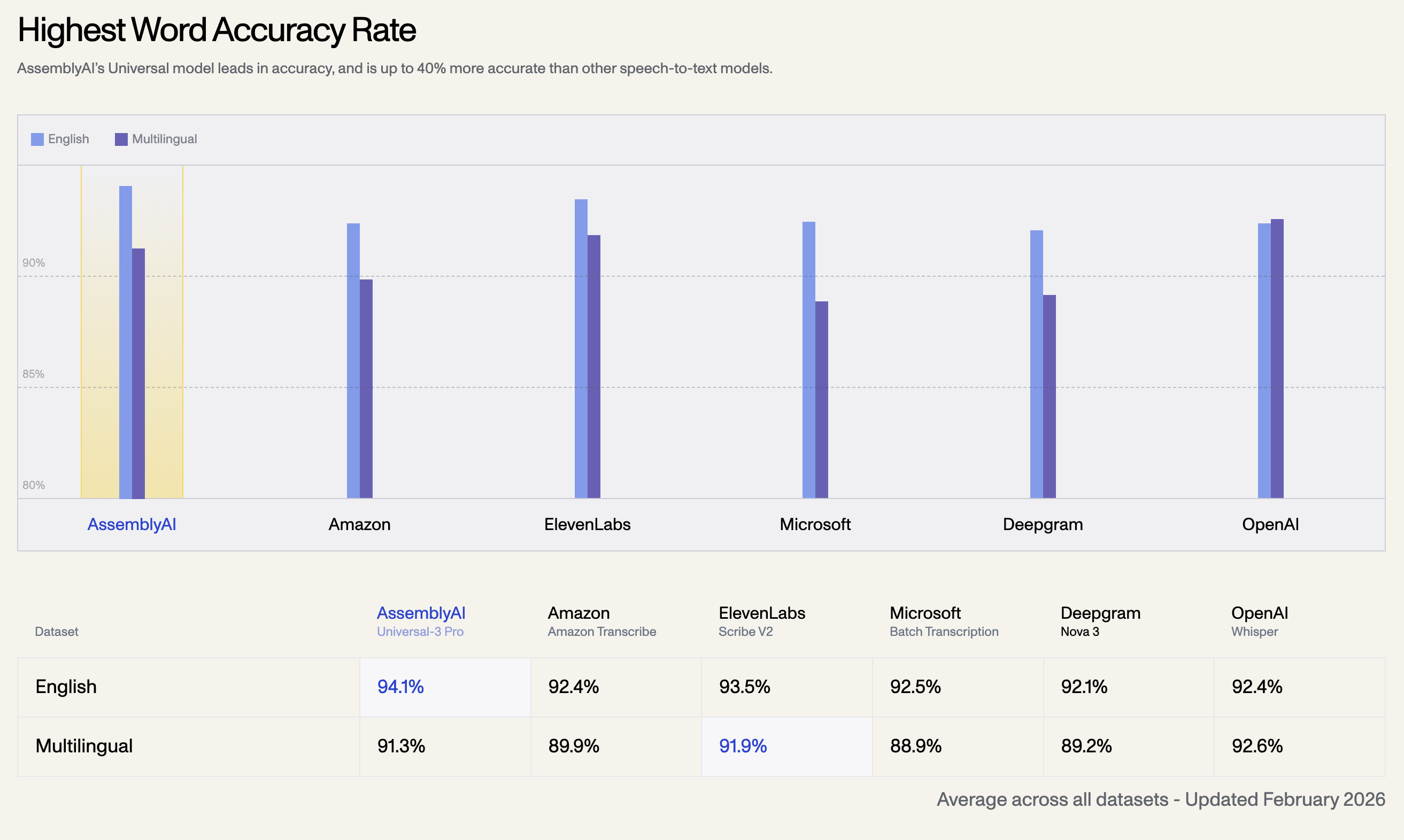
1. En Yüksek Kelime Doğruluk Oranı
AssemblyAI'ın Universal modeli doğrulukta liderdir ve diğer konuşmadan metne modellerinden %40'a kadar daha doğrudur. Aşağıda, Şubat 2026'da güncellenen tüm veri setlerindeki ortalama doğruluk oranı bulunmaktadır:
| Dil Veri Seti | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| İngilizce | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Çok Dilli | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. En Düşük Kelime Hata Oranı (WER)
Daha az hata, özetler, müşteri içgörüleri, meta veri etiketleme, eylem öğeleri ve daha fazlası dahil olmak üzere ses verileri etrafında başarılı yapay zeka uygulamaları oluşturmak için kritik öneme sahiptir.
| Dil Veri Seti | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| İngilizce | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Çok Dilli | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Veri Seti Başına Detaylı İngilizce Kelime Hata Oranı
| Veri Seti | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Gürültülü | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Yayın (dahili) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Kazanç 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Web Semineri | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Ortalama | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Ardışık Hata Türleri ve Halüsinasyon Azaltmaları
Universal, Whisper Large-v3'e kıyasla halüsinasyon oranlarında %30'luk bir azalma göstermektedir. Halüsinasyonları, ses saati başına beş veya daha fazla ardışık ekleme, değiştirme veya silme olarak tanımlıyoruz.
| Ardışık Hata Metriği (İngilizce) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Uydurmalar | 6.6% | 7.9% |
| Atlamalar | 5.3% | 5.5% |
| Halüsinasyonlar | 7.3% | 7.8% |
Gerçek Dünya Halüsinasyon Karşılaştırması
| Zemin Gerçekliği | AssemblyAI Universal-3 Pro | OpenAI Whisper (Halüsinasyon) |
|---|---|---|
| her jewelry shimmered | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| the englishman said nothing | the englishman said nothing | does that mean we should not have interessant n |
| not in a month of sundays | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Özellik Bazında Karşılaştırma
Whisper'ı kendiniz çalıştırmak, GPU'ya, sıraya, güvenilirliğe ve yol haritasına sahip olmak anlamına gelir. AssemblyAI'ın sektör lideri modelini ve yönetilen API'sini başlıca endüstri kıyaslamalarında karşılaştırın.
| Özellik | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Kelime Doğruluk Oranı | 94.1% | 92.4% |
| CommonVoice Kelime Hata Oranı (İngilizce) | 4.13% | 8.52% |
| Gürültülü Kelime Hata Oranı (İngilizce) | 9.97% | 11.63% |
| Konuşmacı Ayırma (Diarization) | ✔ Evet (Yerleşik) | ❌ |
| Kişisel Bilgi Gizleme (PII Redaction) | ✔ Evet (Yerleşik) | ❌ |
| Özetleme | ✔ Evet (Yerleşik) | ❌ |
| Duygu Analizi | ✔ Evet (Yerleşik) | ❌ |
| Akış Konuşmadan Metne | ✔ Evet (Yerleşik) | Yerel yetenekleri yok |
SRTGen Altyazı Oluşturucusunu Neden Universal-3 Pro ile Güçlendiriyor?
SRTGen Altyazı Çalışma Alanı'nı tasarlarken amacımız, profesyonel editörlere, UGC içerik oluşturucularına ve işletmelere mevcut en hızlı ve en doğru altyazı aracını sunmaktı. Whisper açık kaynaklı olsa da, özel Whisper GPU kümelerini büyük ölçekte yönetmek pahalıdır ve ham metni ileri geri aktarmak, profesyonel düzeyde altyazılar için gereken hassas kelime düzeyinde hizalama veya konuşmacı segmentasyonu sağlamaz.
AssemblyAI Universal-3 Pro'yu birincil transkripsiyon motorumuz olarak seçerek, birkaç önemli avantaj elde ediyoruz:
- Kusursuz Kelime Kelime Hizalama: Premium karaoke tarzı animasyonlarımız için her hecenin tam olarak ne zaman konuşulduğunu bilmemiz gerekiyor. Universal-3 Pro, kelimelerin büyük çoğunluğunun gerçek konuşma penceresinin 200 ms içinde hizalandığı zaman damgası hassasiyeti sunar.
- Anında Konuşmacı Etiketleme: Videonuz bir röportaj, podcast veya birden fazla oyuncu içeriyorsa, çalışma alanımız diyaloğu konuşmacıya göre otomatik olarak ayırır, böylece altyazı kartlarını sorunsuz bir şekilde renk kodlayabilir ve gruplayabilirsiniz.
- Sıfır Altyapı Gecikmesi: Hesaplama kaynaklarını biz yönetiriz. Kontrol panelimize bir video yüklediğinizde, ses çıkarımını ve paralel API transkripsiyonunu anında gerçekleştiririz, böylece CPU veya GPU kaynaklarınızı tüketmeden bir dakikadan kısa sürede eksiksiz bir altyazı taslağı elde edersiniz.
Sonuç: Doğru Motoru Seçmek
Kendi kendine barındırma, çevrimdışı işlemler veya ham GPU'ları çalıştırmanın daha uygun maliyetli olduğu bir ölçekte işletme için katı gereksinimleriniz varsa, OpenAI's Whisper'ı kendi kendine barındırmak sağlam bir yoldur.
Ancak, önceliğiniz **anında doğruluk, sağlam alfanümerik biçimlendirme, temiz zaman damgaları ve yerleşik konuşmacı etiketleme** ise, **Universal-3 Pro**'nun yönetilen zekası açık ara galip gelir. Universal-3 Pro'yu arka planda kullanarak, SRTGen üst düzey doğruluğu sektör lideri stil panomuzla birleştirerek size her iki dünyanın da en iyisini sunar.
Universal-3 Pro'nun hassasiyetini kendiniz deneyimleyin. Videolarınızı bugün transkripte etmeye ve biçimlendirmeye başlamak için SRTGen Çalışma Alanı'na gidin!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



