Universal-3 Pro vs. Whisper: Welches Speech-to-Text-Modell ist besser?

Universal-3 Pro vs. Whisper: Welches Speech-to-Text-Modell ist besser?
Die automatische Spracherkennung (ASR) hat einen massiven Paradigmenwechsel erfahren. Die Einführung von auf Deep Learning basierenden Sprachmodellen hat die Genauigkeit der Rohtranskription näher an die menschliche Gleichwertigkeit gebracht als je zuvor. Für Entwickler, die Tools zur Medienlokalisierung, Videountertitel-Editoren und Sprachanalyse-Suiten entwickeln, ist die Wahl des richtigen Backend-Modells eine kritische Entscheidung, die sich direkt auf die Benutzererfahrung und die Rechenkosten auswirkt.
Heute sind die beiden Schwergewichte der Speech-to-Text-Landschaft OpenAI's Whisper (insbesondere Whisper large-v3) und AssemblyAI's Universal-3 Pro. Während Whisper zum beliebten Open-Source-Standard geworden ist, hat sich Universal-3 Pro als führende verwaltete Unternehmenslösung etabliert.
Bei SRTGen haben wir beide Modelle ausgiebig für unseren professionellen Untertitel-Arbeitsbereich evaluiert. Heute teilen wir unsere Benchmark-Analyse, erklären, warum wir unseren Arbeitsbereich letztendlich um AssemblyAI Universal-3 Pro herum aufgebaut haben, und analysieren, wie beide Modelle in Bezug auf Genauigkeit, Halluzinationen, Formatierung und Funktionsumfang abschneiden.
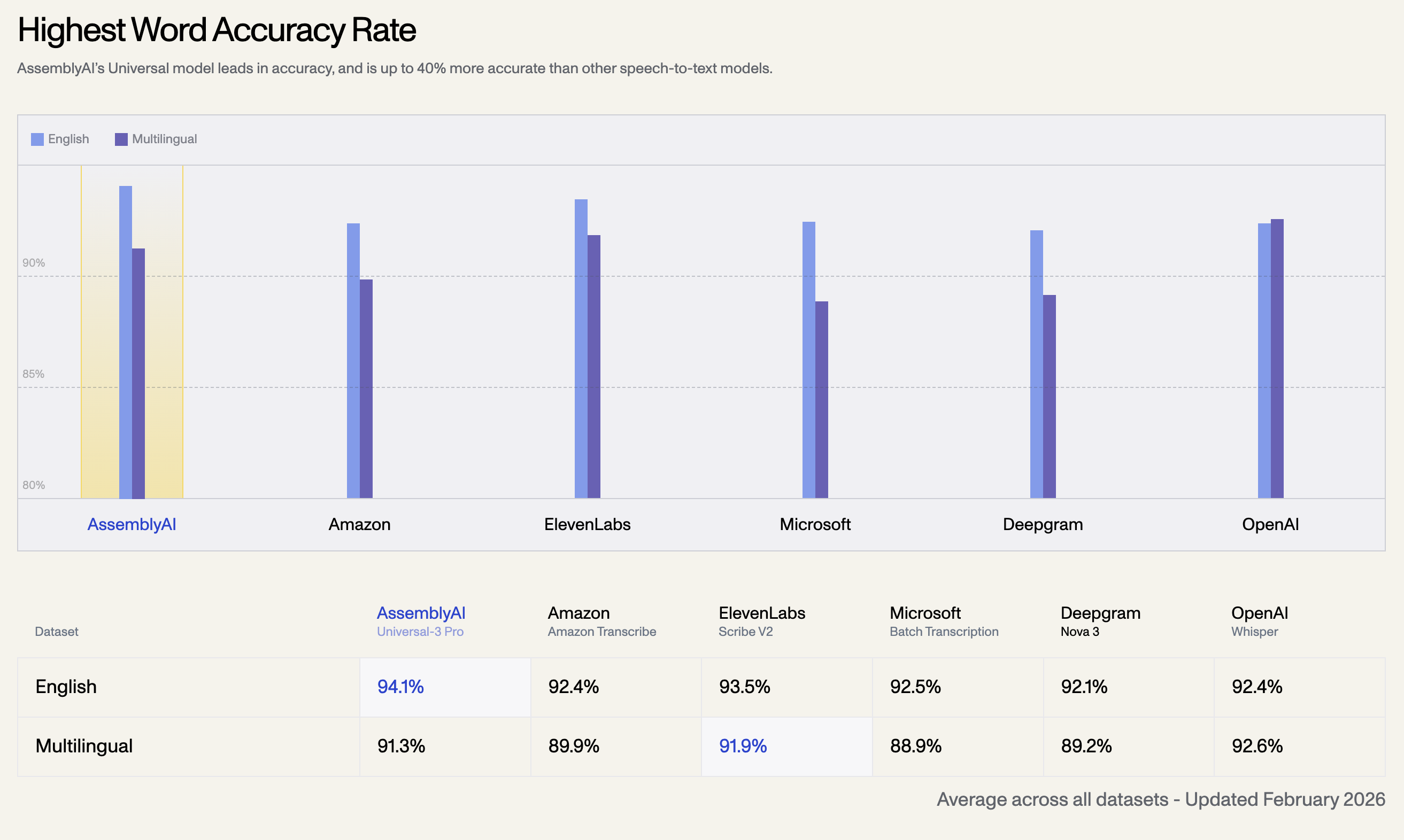
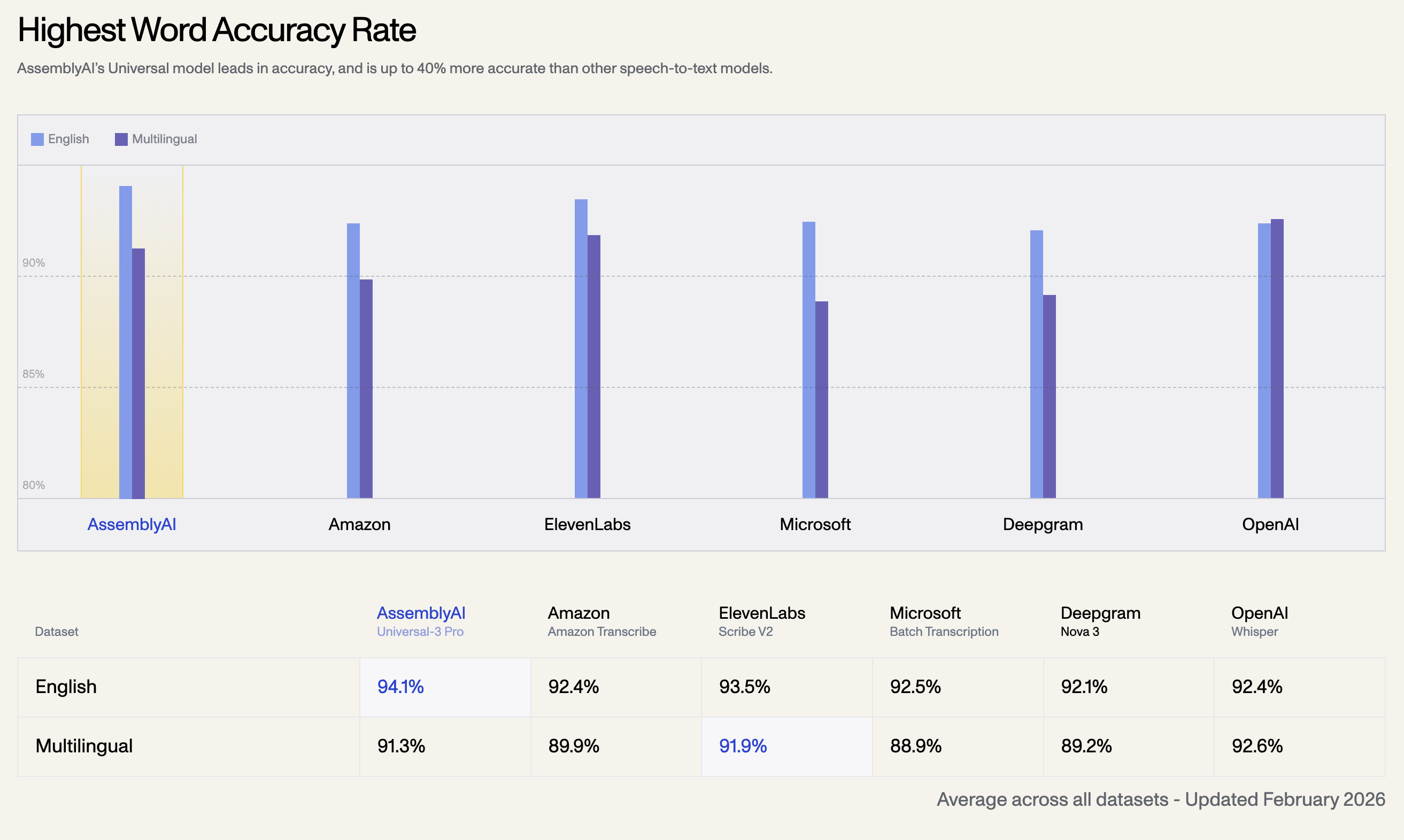
1. Höchste Wortgenauigkeitsrate
Das Universal-Modell von AssemblyAI ist führend in puncto Genauigkeit und bis zu 40 % genauer als andere Speech-to-Text-Modelle. Nachfolgend finden Sie die durchschnittliche Genauigkeitsrate über alle Datensätze hinweg, Stand Februar 2026:
| Sprachdatensatz | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Englisch | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Mehrsprachig | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Niedrigste Wortfehlerrate (WER)
Weniger Fehler sind entscheidend für den Aufbau erfolgreicher KI-Anwendungen rund um Sprachdaten – einschließlich Zusammenfassungen, Kundeninformationen, Metadaten-Tagging, Aktionspunkten und vielem mehr.
| Sprachdatensatz | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Englisch | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Mehrsprachig | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Detaillierte englische Wortfehlerrate pro Datensatz
| Datensatz | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Noisy | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Broadcast (intern) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Earnings 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Durchschnitt | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Konsekutive Fehlertypen & Reduzierung von Halluzinationen
Universal zeigt eine Reduzierung der Halluzinationsraten um 30 % im Vergleich zu Whisper Large-v3. Wir definieren Halluzinationen als fünf oder mehr aufeinanderfolgende Einfügungen, Ersetzungen oder Löschungen pro Audiostunde.
| Metrik für konsekutive Fehler (Englisch) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabrikationen | 6.6% | 7.9% |
| Auslassungen | 5.3% | 5.5% |
| Halluzinationen | 7.3% | 7.8% |
Vergleich von Halluzinationen in der Praxis
| Grundwahrheit | AssemblyAI Universal-3 Pro | OpenAI Whisper (Hallucination) |
|---|---|---|
| ihr Schmuck schimmerte | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| die Taebaek-Gebirgskette wird oft als Rückgrat der Koreanischen Halbinsel angesehen | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| der Engländer sagte nichts | the englishman said nothing | does that mean we should not have interessant n |
| niemals | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Feature-für-Feature-Vergleich
Whisper selbst zu betreiben bedeutet, die Verantwortung für GPU, Warteschlange, Zuverlässigkeit und Roadmap zu tragen. Vergleichen Sie das branchenführende Modell und die verwaltete API von AssemblyAI anhand wichtiger Branchen-Benchmarks.
| Funktion | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Wortgenauigkeitsrate | 94.1% | 92.4% |
| CommonVoice Wortfehlerrate (Englisch) | 4.13% | 8.52% |
| Noisy Wortfehlerrate (Englisch) | 9.97% | 11.63% |
| Sprecher-Diarisierung | ✔ Ja (Integriert) | ❌ |
| PII-Redaktion | ✔ Ja (Integriert) | ❌ |
| Zusammenfassung | ✔ Ja (Integriert) | ❌ |
| Stimmungsanalyse | ✔ Ja (Integriert) | ❌ |
| Streaming Speech-to-Text | ✔ Ja (Integriert) | Keine nativen Funktionen |
Warum SRTGen seinen Untertitel-Generator mit Universal-3 Pro betreibt
Als wir den SRTGen Untertitel-Arbeitsbereich entwickelten, war es unser Ziel, professionellen Editoren, UGC-Erstellern und Unternehmen das schnellste und genaueste verfügbare Untertitelungs-Tool anzubieten. Obwohl Whisper Open-Source ist, ist die Verwaltung kundenspezifischer Whisper-GPU-Cluster im großen Maßstab teuer, und das Hin- und Herschieben von Rohtext liefert uns nicht die präzise Wort-für-Wort-Ausrichtung oder Sprechersegmentierung, die für professionelle Untertitel erforderlich sind.
Durch die Wahl von AssemblyAI Universal-3 Pro als unsere primäre Transkriptions-Engine erzielen wir mehrere entscheidende Vorteile:
- Makellose Wort-für-Wort-Ausrichtung: Für unsere hochwertigen Animationen im Karaoke-Stil müssen wir genau wissen, wann jede einzelne Silbe gesprochen wird. Universal-3 Pro liefert eine Zeitstempelpräzision, bei der die überwiegende Mehrheit der Wörter innerhalb von 200 ms ihres tatsächlichen Sprechfensters ausgerichtet ist.
- Sofortige Sprechererkennung: Wenn Ihr Video ein Interview, einen Podcast oder mehrere Akteure enthält, segmentiert unser Arbeitsbereich den Dialog automatisch nach Sprecher, sodass Sie Untertitelkarten nahtlos farblich kodieren und gruppieren können.
- Keine Infrastruktur-Latenz: Wir kümmern uns um die Rechenressourcen. Wenn Sie ein Video in unserem Dashboard hochladen, übernehmen wir sofort die Audioextraktion und parallele API-Transkription, wodurch Sie in weniger als einer Minute einen vollständigen Untertitel-Entwurf erhalten, ohne Ihre CPU- oder GPU-Ressourcen zu verbrauchen.
Fazit: Die Wahl der richtigen Engine
Wenn Sie strenge Anforderungen an das Self-Hosting, den Offline-Betrieb haben oder in einem Umfang arbeiten, in dem der Betrieb von Roh-GPUs kostengünstiger ist, ist das Self-Hosting von OpenAI's Whisper ein solider Weg.
Wenn Ihre Priorität jedoch auf **sofortiger Genauigkeit, robuster alphanumerischer Formatierung, sauberen Zeitstempeln und integrierter Sprechererkennung** liegt, ist die verwaltete Intelligenz von **Universal-3 Pro** der klare Gewinner. Durch den Einsatz von Universal-3 Pro im Hintergrund kombiniert SRTGen erstklassige Genauigkeit mit unserem branchenführenden Styling-Dashboard und bietet Ihnen das Beste aus beiden Welten.
Erleben Sie selbst die Präzision von Universal-3 Pro. Gehen Sie zum SRTGen Arbeitsbereich und beginnen Sie noch heute mit der Transkription und Gestaltung Ihrer Videos!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



