Universal-3 Pro vs Whisper: ¿Qué modelo de voz a texto es mejor?

Universal-3 Pro vs Whisper: ¿Qué modelo de voz a texto es mejor?
El Reconocimiento Automático de Voz (ASR) ha experimentado un cambio de paradigma masivo. La llegada de modelos de voz basados en aprendizaje profundo ha impulsado la precisión de la transcripción bruta más cerca que nunca de la paridad humana. Para los desarrolladores que crean herramientas de localización de medios, editores de subtítulos de video y suites de análisis de voz, elegir el modelo de backend adecuado es una decisión crítica que impacta directamente la experiencia del usuario y los costos computacionales.
Hoy, los dos pesos pesados del panorama de Voz a Texto son OpenAI's Whisper (específicamente Whisper large-v3) y AssemblyAI's Universal-3 Pro. Si bien Whisper se ha convertido en el favorito de código abierto por defecto, Universal-3 Pro se ha establecido como la alternativa gestionada líder de nivel empresarial.
En SRTGen, evaluamos ambos modelos exhaustivamente para nuestro espacio de trabajo de subtítulos profesional. Hoy, compartimos nuestro análisis de referencia, explicando por qué finalmente construimos nuestro espacio de trabajo alrededor de AssemblyAI Universal-3 Pro, y desglosando cómo se comparan ambos modelos en cuanto a precisión, alucinaciones, formato y conjuntos de características.
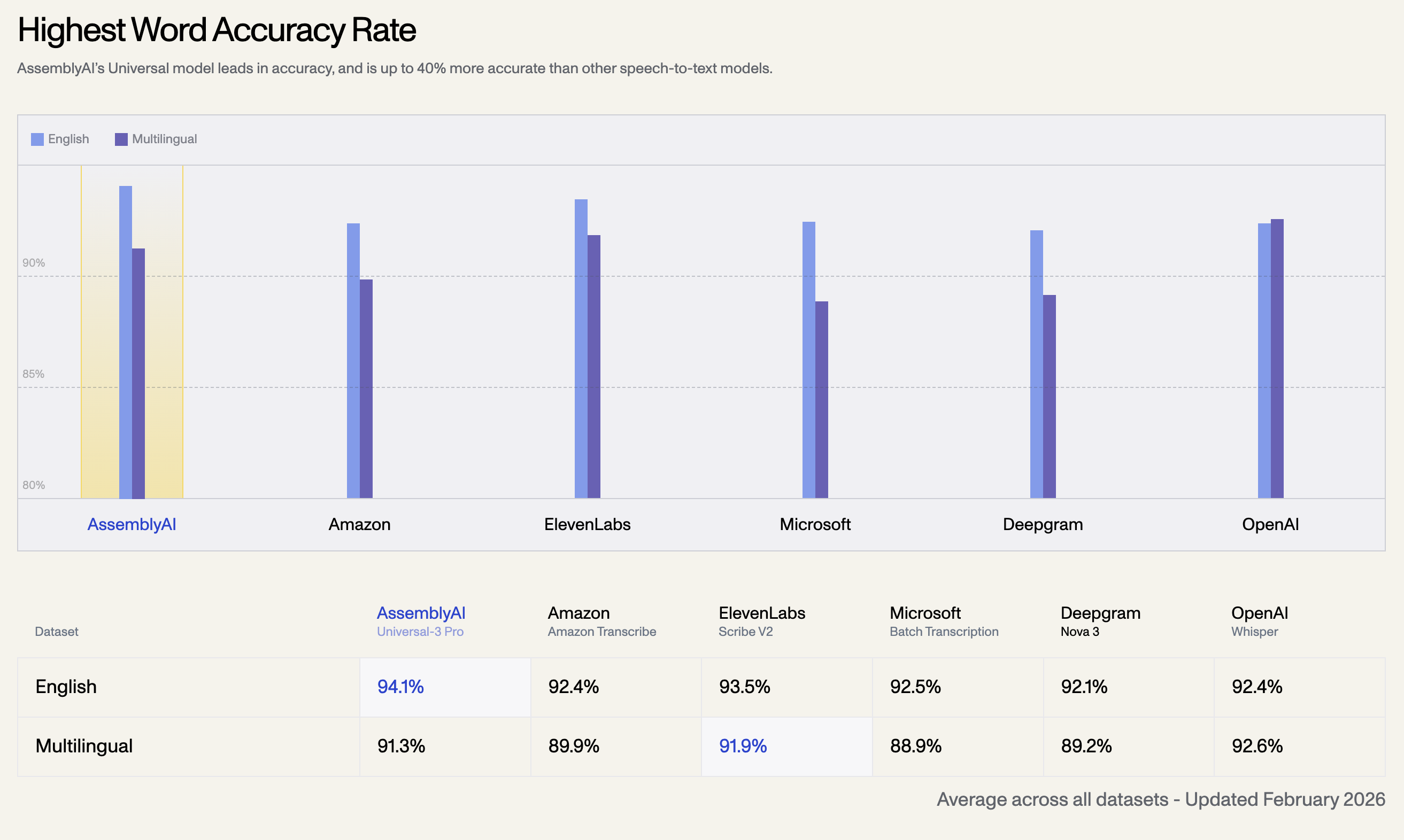
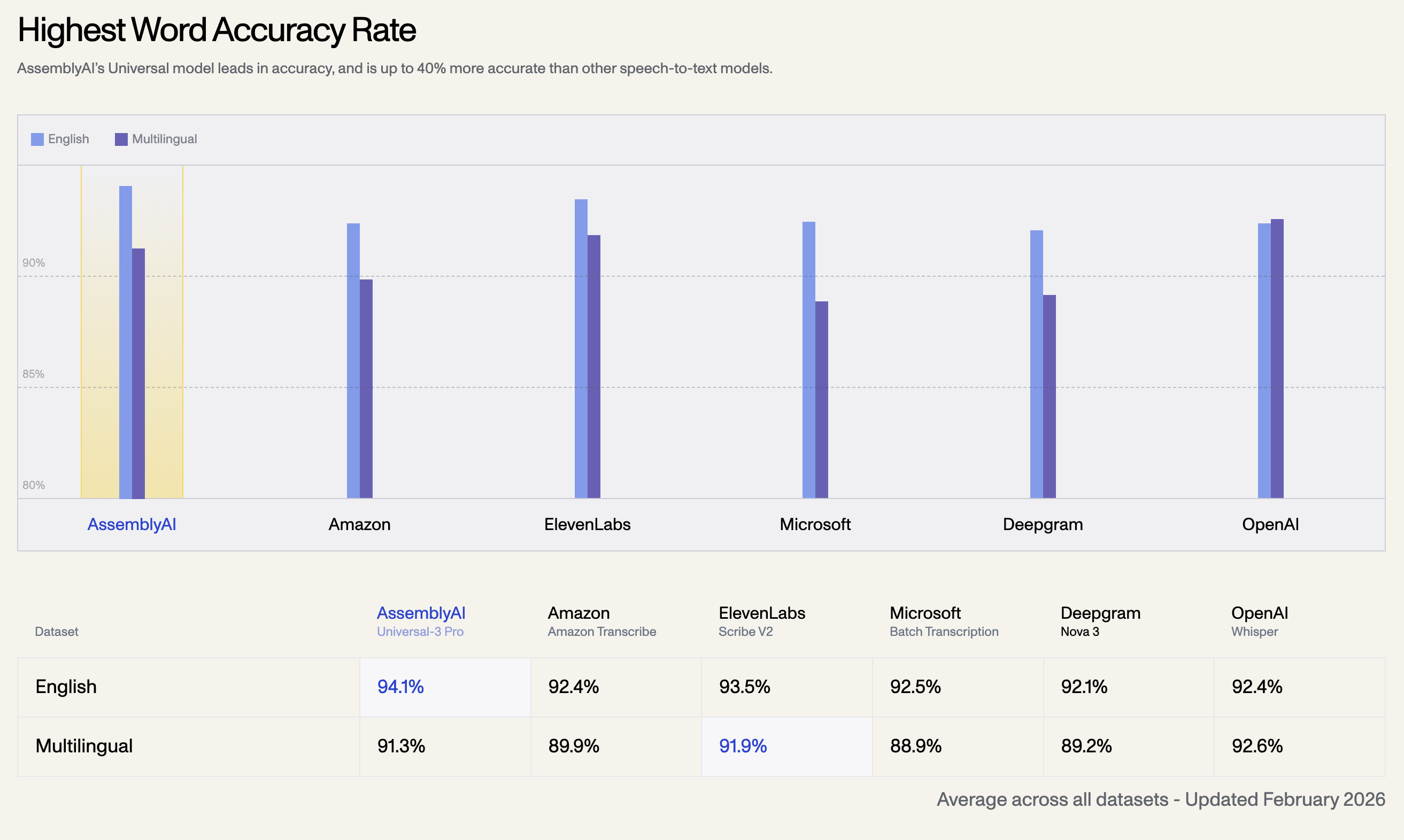
1. Tasa de Precisión de Palabras Más Alta
El modelo Universal de AssemblyAI lidera en precisión, siendo hasta un 40% más preciso que otros modelos de voz a texto. A continuación, se muestra la tasa de precisión promedio en todos los conjuntos de datos, actualizada en febrero de 2026:
| Conjunto de Datos de Idioma | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglés | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Multilingüe | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Tasa de Error de Palabras (WER) Más Baja
Un menor número de errores es fundamental para construir aplicaciones de IA exitosas en torno a los datos de voz, incluyendo resúmenes, información del cliente, etiquetado de metadatos, elementos de acción y más.
| Conjunto de Datos de Idioma | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglés | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Multilingüe | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Tasa Detallada de Error de Palabras en Inglés por Conjunto de Datos
| Conjunto de Datos | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Noisy | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Broadcast (internal) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Earnings 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Promedio | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Tipos de Error Consecutivos y Reducción de Alucinaciones
Universal muestra una reducción del 30% en las tasas de alucinación en comparación con Whisper Large-v3. Definimos las alucinaciones como cinco o más inserciones, sustituciones o eliminaciones consecutivas por hora de audio.
| Métrica de Error Consecutivo (Inglés) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabricaciones | 6.6% | 7.9% |
| Omisiones | 5.3% | 5.5% |
| Alucinaciones | 7.3% | 7.8% |
Comparación de Alucinaciones en el Mundo Real
| Verdad fundamental | AssemblyAI Universal-3 Pro | OpenAI Whisper (Alucinación) |
|---|---|---|
| su joya brillaba | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| la cadena montañosa Taebaek a menudo se considera la columna vertebral de la península coreana | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| el inglés no dijo nada | the englishman said nothing | does that mean we should not have interessant n |
| ni en un millón de años | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Comparación Característica por Característica
Ejecutar Whisper por tu cuenta significa ser propietario de la GPU, la cola, la fiabilidad y la hoja de ruta. Compara el modelo líder en la industria de AssemblyAI y su API gestionada con los principales puntos de referencia de la industria.
| Característica | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Tasa de Precisión de Palabras | 94.1% | 92.4% |
| Tasa de Error de Palabras CommonVoice (Inglés) | 4.13% | 8.52% |
| Tasa de Error de Palabras en Entorno Ruidoso (Inglés) | 9.97% | 11.63% |
| Diarización de Locutores | ✔ Sí (Integrado) | ❌ |
| Redacción de PII | ✔ Sí (Integrado) | ❌ |
| Resumen | ✔ Sí (Integrado) | ❌ |
| Análisis de Sentimiento | ✔ Sí (Integrado) | ❌ |
| Voz a Texto en Tiempo Real | ✔ Sí (Integrado) | Sin capacidades nativas |
Por qué SRTGen Impulsa su Generador de Subtítulos con Universal-3 Pro
Cuando diseñamos el Espacio de Trabajo de Subtítulos de SRTGen, nuestro objetivo era ofrecer a los editores profesionales, creadores de UGC y empresas la herramienta de subtitulado más rápida y precisa disponible. Si bien Whisper es de código abierto, gestionar clústeres de GPU personalizados de Whisper a escala es costoso, y pasar texto sin procesar de un lado a otro no nos proporciona la alineación precisa a nivel de palabra o la segmentación de hablantes necesaria para subtítulos de calidad profesional.
Al seleccionar AssemblyAI Universal-3 Pro como nuestro motor de transcripción principal, obtenemos varias ventajas clave:
- Alineación Palabra por Palabra Impecable: Para nuestras animaciones premium al estilo karaoke, necesitamos saber exactamente cuándo se pronuncia cada sílaba. Universal-3 Pro ofrece una precisión de marca de tiempo donde la gran mayoría de las palabras se alinean dentro de los 200 ms de su ventana de habla real.
- Etiquetado Instantáneo de Locutores: Si tu video presenta una entrevista, un podcast o varios actores, nuestro espacio de trabajo segmenta automáticamente el diálogo por locutor, permitiéndote codificar por colores y agrupar las tarjetas de subtítulos sin problemas.
- Latencia de Infraestructura Cero: Nosotros manejamos los recursos informáticos. Cuando subes un video a nuestro panel de control, nos encargamos de la extracción de audio y la transcripción API paralela al instante, brindándote un borrador de subtítulos completo en menos de un minuto sin consumir tus recursos de CPU o GPU.
Conclusión: Elegir el Motor Correcto
Si tienes requisitos estrictos para el autoalojamiento, operaciones fuera de línea o estás operando a una escala donde ejecutar GPUs directamente es más rentable, el autoalojamiento de OpenAI's Whisper es una opción sólida.
Sin embargo, si tu prioridad es la **precisión inmediata, un formato alfanumérico robusto, marcas de tiempo limpias y el etiquetado de locutores integrado**, la inteligencia gestionada de **Universal-3 Pro** es el claro ganador. Al utilizar Universal-3 Pro entre bastidores, SRTGen combina una precisión de primer nivel con nuestro panel de estilo líder en la industria, ofreciéndote lo mejor de ambos mundos.
Experimenta la precisión de Universal-3 Pro tú mismo. Dirígete al Espacio de Trabajo de SRTGen para empezar a transcribir y dar estilo a tus videos hoy mismo!
David Lin
Fundador, SRTGen
Creador de video y desarrollador enfocado en construir herramientas de automatización profesionales.



