Universal-3 Pro vs Whisper: Qual è il modello di Speech-to-Text migliore?

Universal-3 Pro vs Whisper: Qual è il modello di Speech-to-Text migliore?
Il Riconoscimento Automatico del Discorso (ASR) ha subito un massiccio cambiamento di paradigma. L'arrivo di modelli vocali basati sul deep learning ha spinto l'accuratezza della trascrizione grezza più vicina che mai alla parità umana. Per gli sviluppatori che creano strumenti di localizzazione multimediale, editor di sottotitoli video e suite di analisi vocale, scegliere il modello di backend giusto è una decisione critica che influenza direttamente l'esperienza utente e i costi computazionali.
Oggi, i due pesi massimi nel panorama dello Speech-to-Text sono Whisper di OpenAI (in particolare Whisper large-v3) e Universal-3 Pro di AssemblyAI. Mentre Whisper è diventato il beniamino open-source predefinito, Universal-3 Pro si è affermato come l'alternativa gestita di livello enterprise leader.
Presso SRTGen, abbiamo valutato entrambi i modelli in modo approfondito per il nostro ambiente di lavoro professionale per sottotitoli. Oggi, condividiamo la nostra analisi comparativa, spiegando perché abbiamo scelto di costruire il nostro ambiente di lavoro attorno a AssemblyAI Universal-3 Pro, e analizzando come entrambi i modelli si confrontano in termini di accuratezza, allucinazioni, formattazione e set di funzionalità.
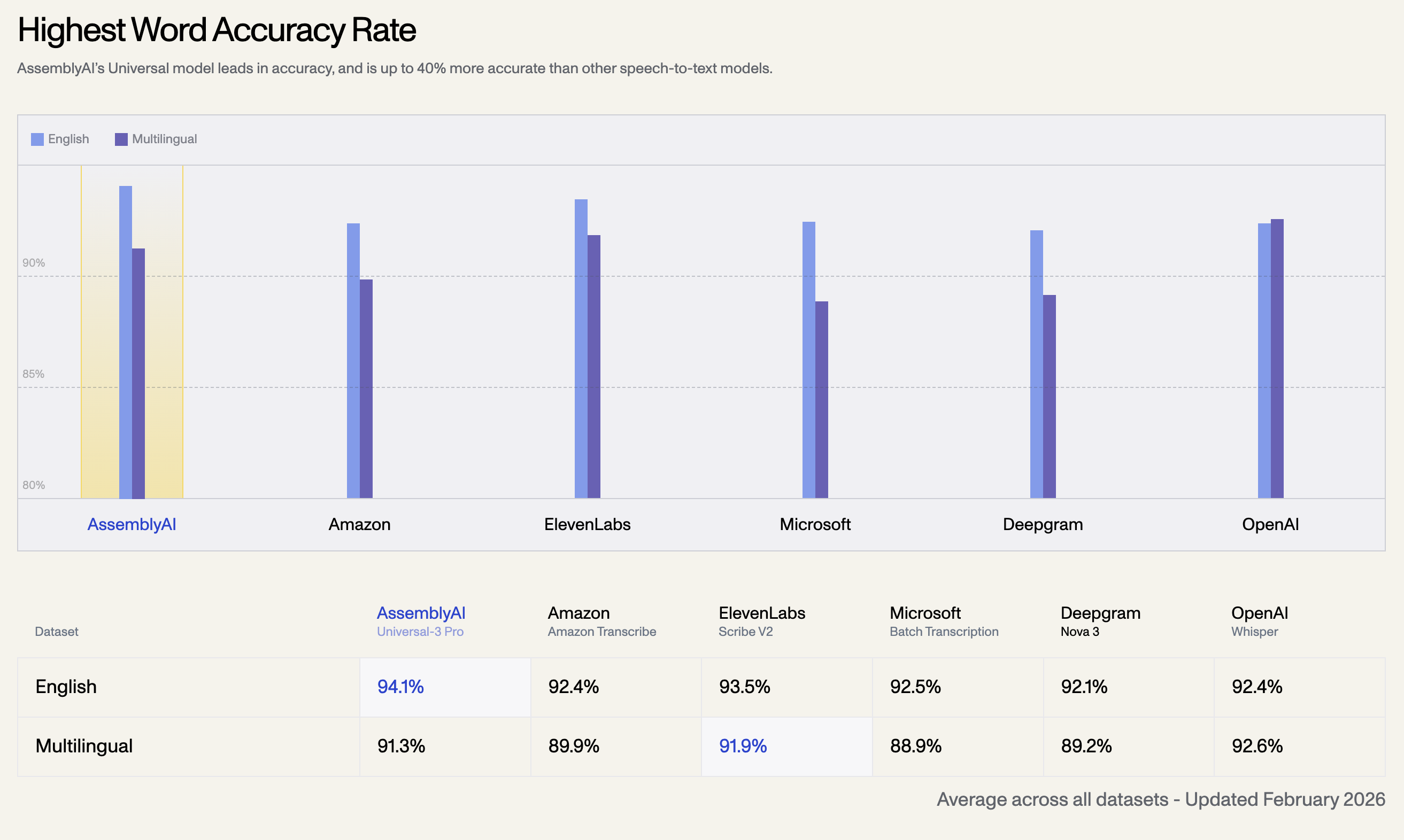
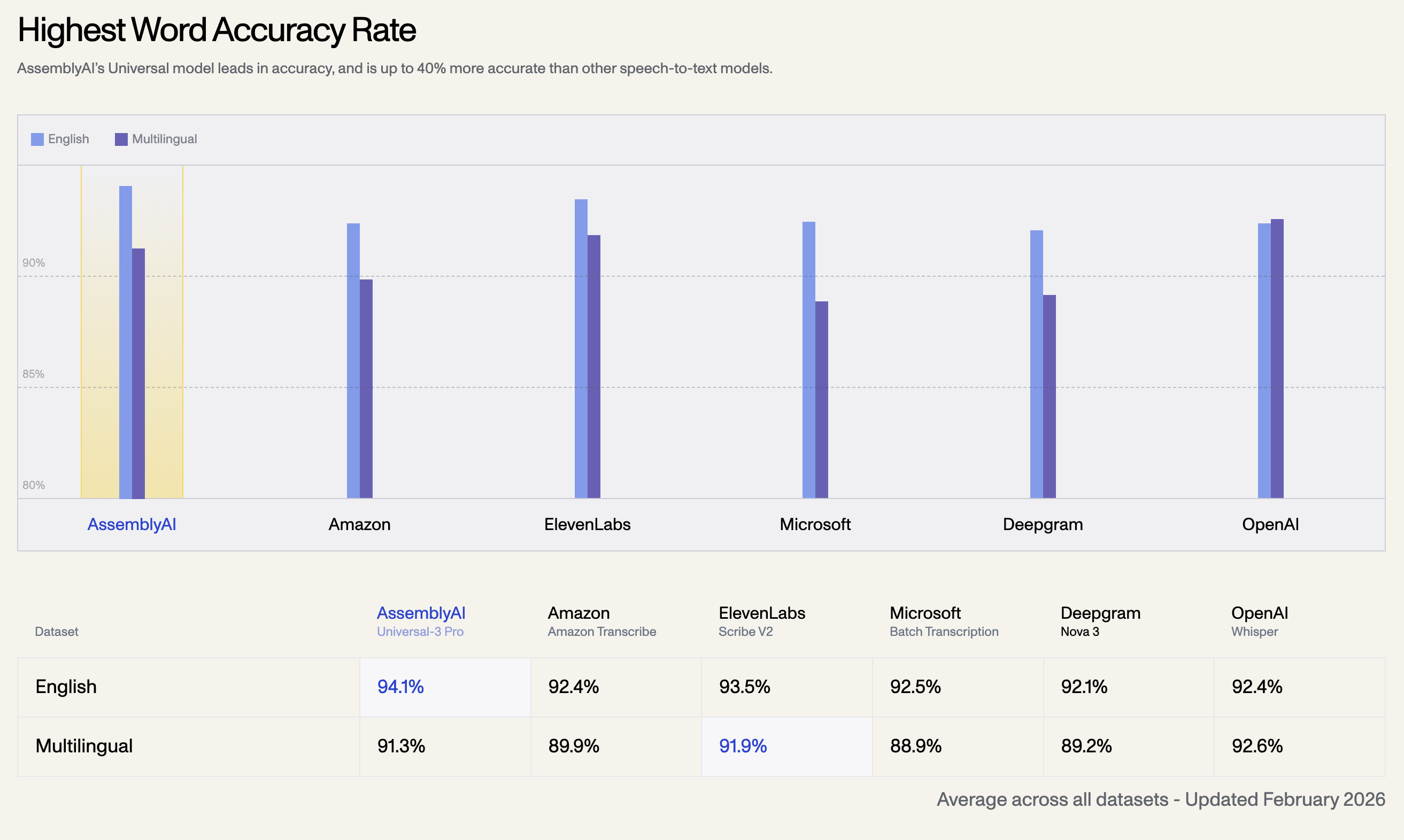
1. Tasso di accuratezza delle parole più elevato
Il modello Universal di AssemblyAI è leader nell'accuratezza ed è fino al 40% più preciso rispetto ad altri modelli di speech-to-text. Di seguito è riportato il tasso di accuratezza medio su tutti i dataset, aggiornato a febbraio 2026:
| Dataset Linguistico | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglese | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Multilingue | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Tasso di errore delle parole (WER) più basso
Un minor numero di errori è fondamentale per la creazione di applicazioni AI di successo basate sui dati vocali, inclusi riassunti, insight sui clienti, tagging di metadati, elementi d'azione e altro ancora.
| Dataset Linguistico | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglese | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Multilingue | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Tasso di errore dettagliato delle parole in inglese per dataset
| Dataset | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Rumoroso | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Pulito | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Altro | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Broadcast (interno) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Utili 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Media | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Tipi di errore consecutivi e Riduzione delle allucinazioni
Universal mostra una riduzione del 30% dei tassi di allucinazione rispetto a Whisper Large-v3. Definiamo le allucinazioni come cinque o più inserzioni, sostituzioni o cancellazioni consecutive per ora audio.
| Metrica degli errori consecutivi (Inglese) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabbricazioni | 6.6% | 7.9% |
| Omissioni | 5.3% | 5.5% |
| Allucinazioni | 7.3% | 7.8% |
Confronto delle allucinazioni nel mondo reale
| Verità oggettiva | AssemblyAI Universal-3 Pro | OpenAI Whisper (Allucinazione) |
|---|---|---|
| her jewelry shimmered | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| the englishman said nothing | the englishman said nothing | does that mean we should not have interessant n |
| not in a month of sundays | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Confronto Funzionalità per Funzionalità
Eseguire Whisper in proprio significa possedere la GPU, la coda, la gestione dell'affidabilità e la roadmap. Confronta il modello e l'API gestita leader del settore di AssemblyAI rispetto ai principali benchmark del settore.
| Funzionalità | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Tasso di Accuratezza delle Parole | 94.1% | 92.4% |
| Tasso di Errore delle Parole CommonVoice (Inglese) | 4.13% | 8.52% |
| Tasso di Errore delle Parole Rumoroso (Inglese) | 9.97% | 11.63% |
| Diarizzazione dei Parlatori | ✔ Sì (Integrata) | ❌ |
| Redazione PII | ✔ Sì (Integrata) | ❌ |
| Riassunto | ✔ Sì (Integrata) | ❌ |
| Analisi del Sentiment | ✔ Sì (Integrata) | ❌ |
| Speech-to-Text in Streaming | ✔ Sì (Integrata) | Nessuna capacità nativa |
Perché SRTGen alimenta il suo generatore di sottotitoli con Universal-3 Pro
Quando abbiamo progettato il SRTGen Subtitle Workspace, il nostro obiettivo era offrire a editor professionali, creatori UGC e aziende lo strumento di sottotitolazione più veloce e accurato disponibile. Sebbene Whisper sia open-source, gestire cluster GPU Whisper personalizzati su larga scala è costoso, e il passaggio di testo grezzo avanti e indietro non ci fornisce l'allineamento preciso a livello di parola o la segmentazione dei parlatori richiesti per sottotitoli di livello professionale.
Selezionando AssemblyAI Universal-3 Pro come nostro motore di trascrizione principale, otteniamo diversi vantaggi chiave:
- Allineamento Parola per Parola Impeccabile: Per le nostre animazioni in stile karaoke premium, dobbiamo sapere esattamente quando viene pronunciata ogni singola sillaba. Universal-3 Pro offre una precisione di timestamp in cui la stragrande maggioranza delle parole è allineata entro 200 ms dalla loro effettiva finestra di parlato.
- Etichettatura Immediata dei Parlatori: Se il tuo video presenta un'intervista, un podcast o più attori, il nostro ambiente di lavoro segmenta automaticamente il dialogo per parlante, permettendoti di codificare a colori e raggruppare le schede dei sottotitoli senza soluzione di continuità.
- Latenza dell'Infrastruttura Zero: Gestiamo noi le risorse di calcolo. Quando carichi un video nella nostra dashboard, gestiamo istantaneamente l'estrazione audio e la trascrizione API parallela, fornendoti una bozza completa dei sottotitoli in meno di un minuto senza consumare le tue risorse CPU o GPU.
Conclusione: Scegliere il Motore Giusto
Se hai requisiti stringenti per l'auto-hosting, operazioni offline o stai operando su una scala in cui l'esecuzione di GPU grezze è più conveniente, l'auto-hosting di Whisper di OpenAI è una strada solida.
Tuttavia, se la tua priorità è **l'accuratezza immediata, una robusta formattazione alfanumerica, timestamp puliti e l'etichettatura integrata dei parlatori**, l'intelligenza gestita di **Universal-3 Pro** è il chiaro vincitore. Utilizzando Universal-3 Pro dietro le quinte, SRTGen combina un'accuratezza di alto livello con la nostra dashboard di stile leader del settore, offrendoti il meglio di entrambi i mondi.
Sperimenta tu stesso la precisione di Universal-3 Pro. Vai allo SRTGen Workspace per iniziare a trascrivere e stilizzare i tuoi video oggi stesso!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



