Universal-3 Pro vs Whisper: Qual Modelo de Fala para Texto é Melhor?

Universal-3 Pro vs Whisper: Qual Modelo de Fala para Texto é Melhor?
O Reconhecimento Automático de Fala (ASR) passou por uma mudança de paradigma massiva. A chegada de modelos de fala baseados em deep learning impulsionou a precisão da transcrição bruta para mais perto da paridade humana do que nunca. Para desenvolvedores que constroem ferramentas de localização de mídia, editores de legendas de vídeo e suítes de análise de fala, escolher o modelo de backend certo é uma decisão crítica que impacta diretamente a experiência do usuário e os custos computacionais.
Hoje, os dois pesos-pesados do cenário de Fala para Texto são o Whisper da OpenAI (especificamente Whisper large-v3) e o Universal-3 Pro da AssemblyAI. Enquanto o Whisper se tornou o queridinho de código aberto padrão, o Universal-3 Pro se estabeleceu como a principal alternativa gerenciada de nível empresarial.
Na SRTGen, avaliamos ambos os modelos extensivamente para nosso espaço de trabalho de legendas profissionais. Hoje, estamos compartilhando nossa análise de benchmark, explicando por que, em última análise, construímos nosso espaço de trabalho em torno do AssemblyAI Universal-3 Pro e detalhando como ambos os modelos se comparam em precisão, alucinações, formatação e conjuntos de recursos.
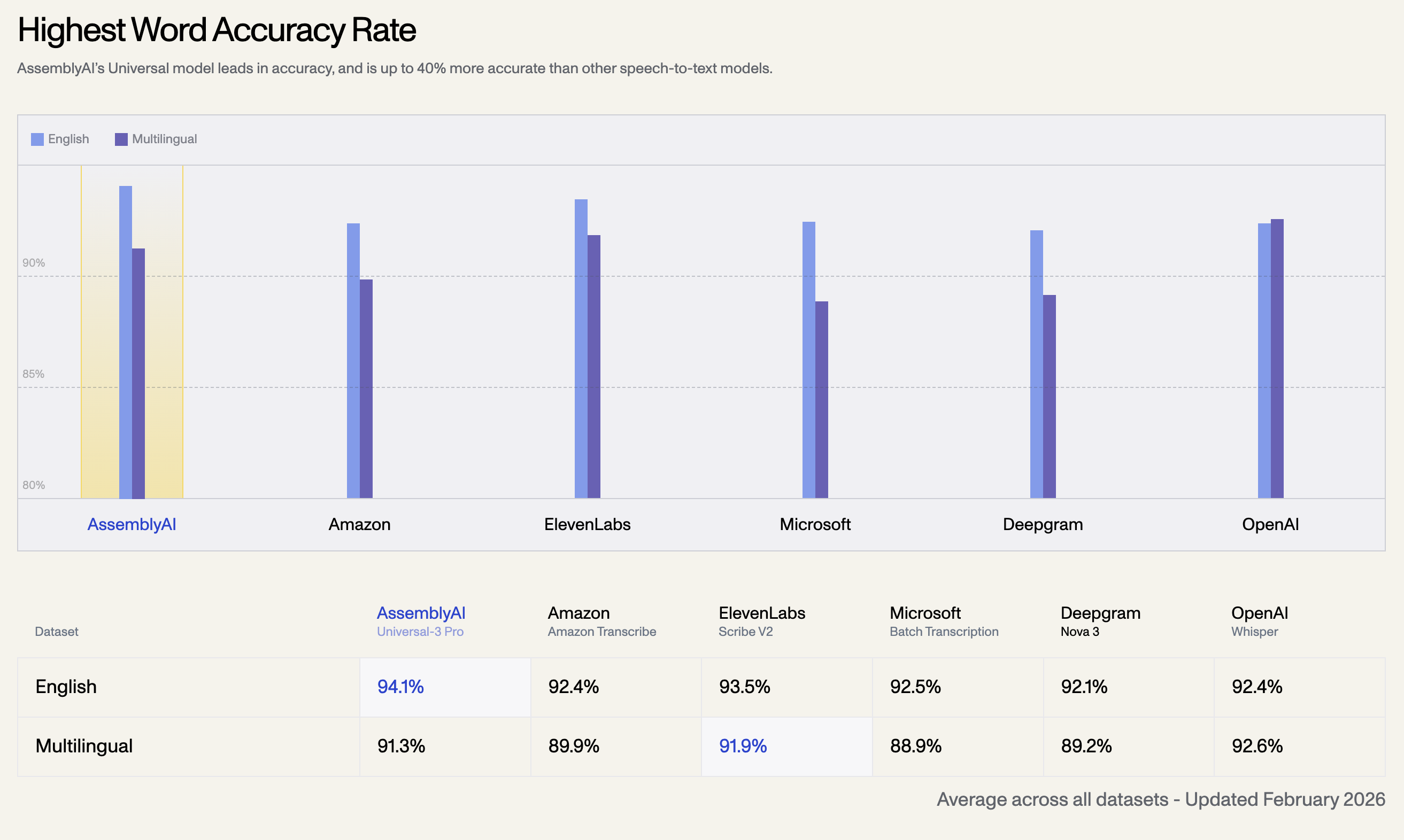
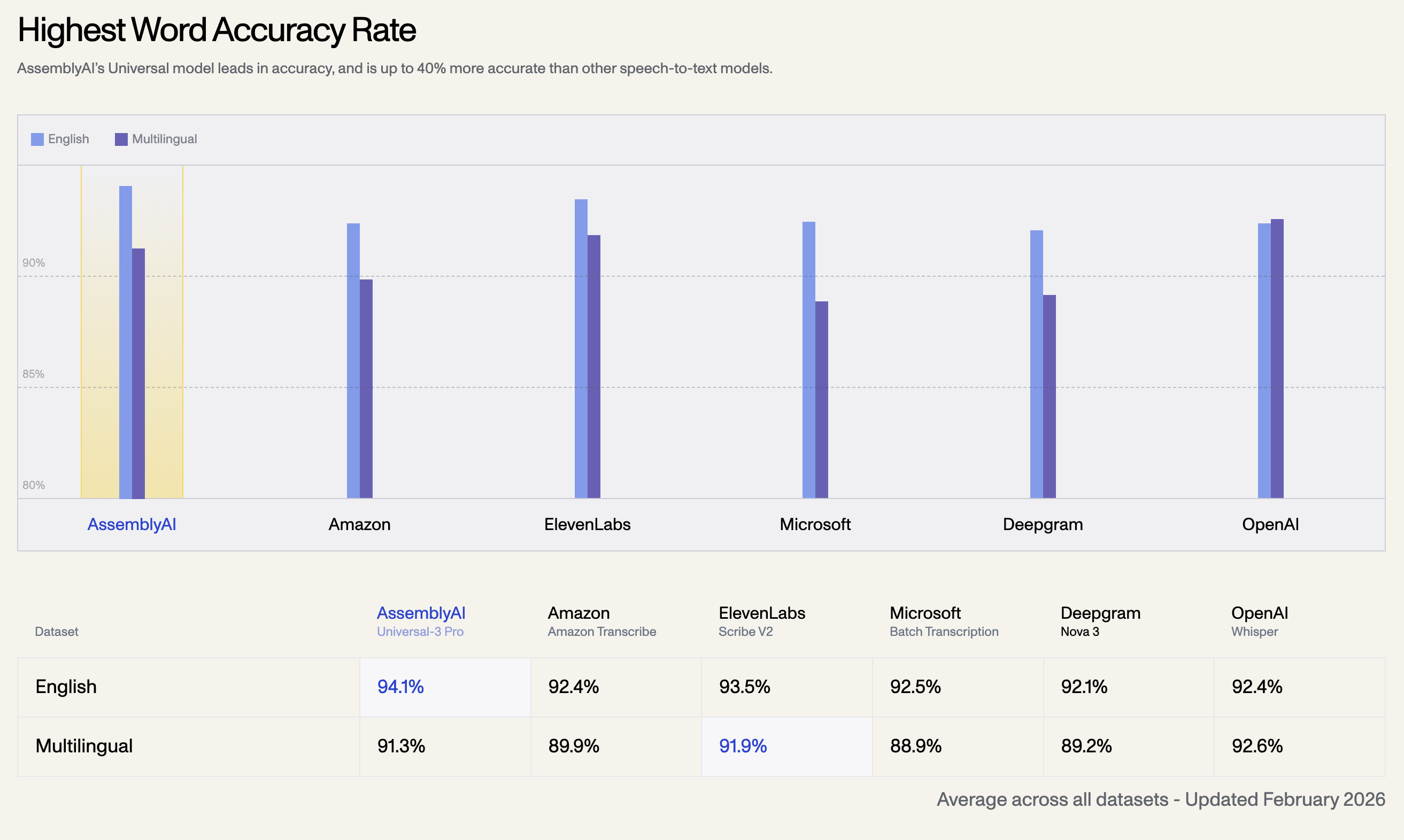
1. Maior Taxa de Precisão de Palavras
O modelo Universal da AssemblyAI lidera em precisão e é até 40% mais preciso que outros modelos de fala para texto. Abaixo está a taxa de precisão média em todos os conjuntos de dados, atualizada em fevereiro de 2026:
| Conjunto de Dados de Idioma | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglês | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Multilíngue | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Menor Taxa de Erro de Palavra (WER)
Menos erros são cruciais para a construção de aplicações de IA bem-sucedidas em torno de dados de voz — incluindo resumos, insights de clientes, marcação de metadados, itens de ação e muito mais.
| Conjunto de Dados de Idioma | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Inglês | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Multilíngue | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Taxa de Erro de Palavra Detalhada em Inglês por Conjunto de Dados
| Conjunto de Dados | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Com Ruído | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Transmissão (interna) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Ganhos 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Média | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Tipos de Erro Consecutivos e Reduções de Alucinação
O Universal mostra uma redução de 30% nas taxas de alucinação em comparação com o Whisper Large-v3. Definimos alucinações como cinco ou mais inserções, substituições ou exclusões consecutivas por hora de áudio.
| Métrica de Erro Consecutivo (Inglês) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabricações | 6.6% | 7.9% |
| Omissões | 5.3% | 5.5% |
| Alucinações | 7.3% | 7.8% |
Comparação de Alucinações no Mundo Real
| Verdade Fundamental | AssemblyAI Universal-3 Pro | OpenAI Whisper (Alucinação) |
|---|---|---|
| her jewelry shimmered | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| the englishman said nothing | the englishman said nothing | does that mean we should not have interessant n |
| not in a month of sundays | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Comparação Recurso a Recurso
Executar o Whisper por conta própria significa ser responsável pela GPU, pela fila, pela confiabilidade e pelo roadmap. Compare o modelo líder da indústria da AssemblyAI e a API gerenciada com os principais benchmarks da indústria.
| Recurso | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Taxa de Precisão de Palavras | 94.1% | 92.4% |
| Taxa de Erro de Palavra CommonVoice (Inglês) | 4.13% | 8.52% |
| Taxa de Erro de Palavra com Ruído (Inglês) | 9.97% | 11.63% |
| Diarização de Voz | ✔ Sim (Integrado) | ❌ |
| Anonimização de PII | ✔ Sim (Integrado) | ❌ |
| Resumo | ✔ Sim (Integrado) | ❌ |
| Análise de Sentimento | ✔ Sim (Integrado) | ❌ |
| Fala para Texto em Tempo Real (Streaming) | ✔ Sim (Integrado) | Sem recursos nativos |
Por Que a SRTGen Otimiza Seu Gerador de Legendas com o Universal-3 Pro
Quando projetamos o Espaço de Trabalho de Legendas da SRTGen, nosso objetivo era oferecer a editores profissionais, criadores de UGC e empresas a ferramenta de legendagem mais rápida e precisa disponível. Embora o Whisper seja de código aberto, gerenciar clusters de GPU Whisper personalizados em escala é caro, e passar texto bruto para lá e para cá não nos fornece o alinhamento preciso ao nível da palavra ou a segmentação do locutor necessários para legendas de nível profissional.
Ao selecionar o AssemblyAI Universal-3 Pro como nosso principal motor de transcrição, obtemos várias vantagens importantes:
- Alinhamento Perfeito Palavra por Palavra: Para nossas animações premium estilo karaokê, precisamos saber exatamente quando cada sílaba é pronunciada. O Universal-3 Pro oferece precisão de carimbo de data/hora onde a grande maioria das palavras é alinhada dentro de 200ms de sua janela de fala real.
- Identificação Instantânea do Locutor: Se o seu vídeo apresenta uma entrevista, um podcast ou vários atores, nosso espaço de trabalho segmenta automaticamente o diálogo por locutor, permitindo que você codifique por cores e agrupe cartões de legenda de forma contínua.
- Latência Zero de Infraestrutura: Nós lidamos com os recursos de computação. Quando você faz upload de um vídeo em nosso painel, nós cuidamos da extração de áudio e da transcrição paralela da API instantaneamente, fornecendo um rascunho completo da legenda em menos de um minuto, sem consumir seus recursos de CPU ou GPU.
Conclusão: Escolhendo o Motor Certo
Se você tem requisitos rigorosos para auto-hospedagem, operações offline ou está operando em uma escala onde a execução de GPUs brutas é mais econômica, auto-hospedar o Whisper da OpenAI é um caminho sólido.
No entanto, se sua prioridade é **precisão imediata, formatação alfanumérica robusta, carimbos de data/hora claros e identificação de locutor integrada**, a inteligência gerenciada do **Universal-3 Pro** é o vencedor claro. Ao utilizar o Universal-3 Pro nos bastidores, a SRTGen combina precisão de alto nível com nosso painel de estilo líder da indústria, proporcionando o melhor dos dois mundos.
Experimente a precisão do Universal-3 Pro por si mesmo. Vá para o Espaço de Trabalho SRTGen para começar a transcrever e estilizar seus vídeos hoje!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



