Universal-3 Pro vs Whisper : Quel est le meilleur modèle de reconnaissance vocale ?

Universal-3 Pro vs Whisper : Quel est le meilleur modèle de reconnaissance vocale ?
La reconnaissance automatique de la parole (ASR) a connu un changement de paradigme majeur. L'arrivée des modèles vocaux basés sur l'apprentissage profond a poussé la précision de la transcription brute plus près que jamais de la parité humaine. Pour les développeurs qui créent des outils de localisation multimédia, des éditeurs de sous-titres vidéo et des suites d'analyse vocale, choisir le bon modèle de backend est une décision cruciale qui impacte directement l'expérience utilisateur et les coûts de calcul.
Aujourd'hui, les deux poids lourds du paysage de la reconnaissance vocale sont Whisper d'OpenAI (en particulier Whisper large-v3) et Universal-3 Pro d'AssemblyAI. Tandis que Whisper est devenu le chouchou par défaut de l'open source, Universal-3 Pro s'est imposé comme l'alternative gérée de pointe pour les entreprises.
Chez SRTGen, nous avons évalué ces deux modèles de manière approfondie pour notre espace de travail professionnel de sous-titres. Aujourd'hui, nous partageons notre analyse comparative, expliquant pourquoi nous avons finalement construit notre espace de travail autour d'AssemblyAI Universal-3 Pro, et détaillant comment les deux modèles se comportent en termes de précision, d'hallucinations, de formatage et d'ensembles de fonctionnalités.
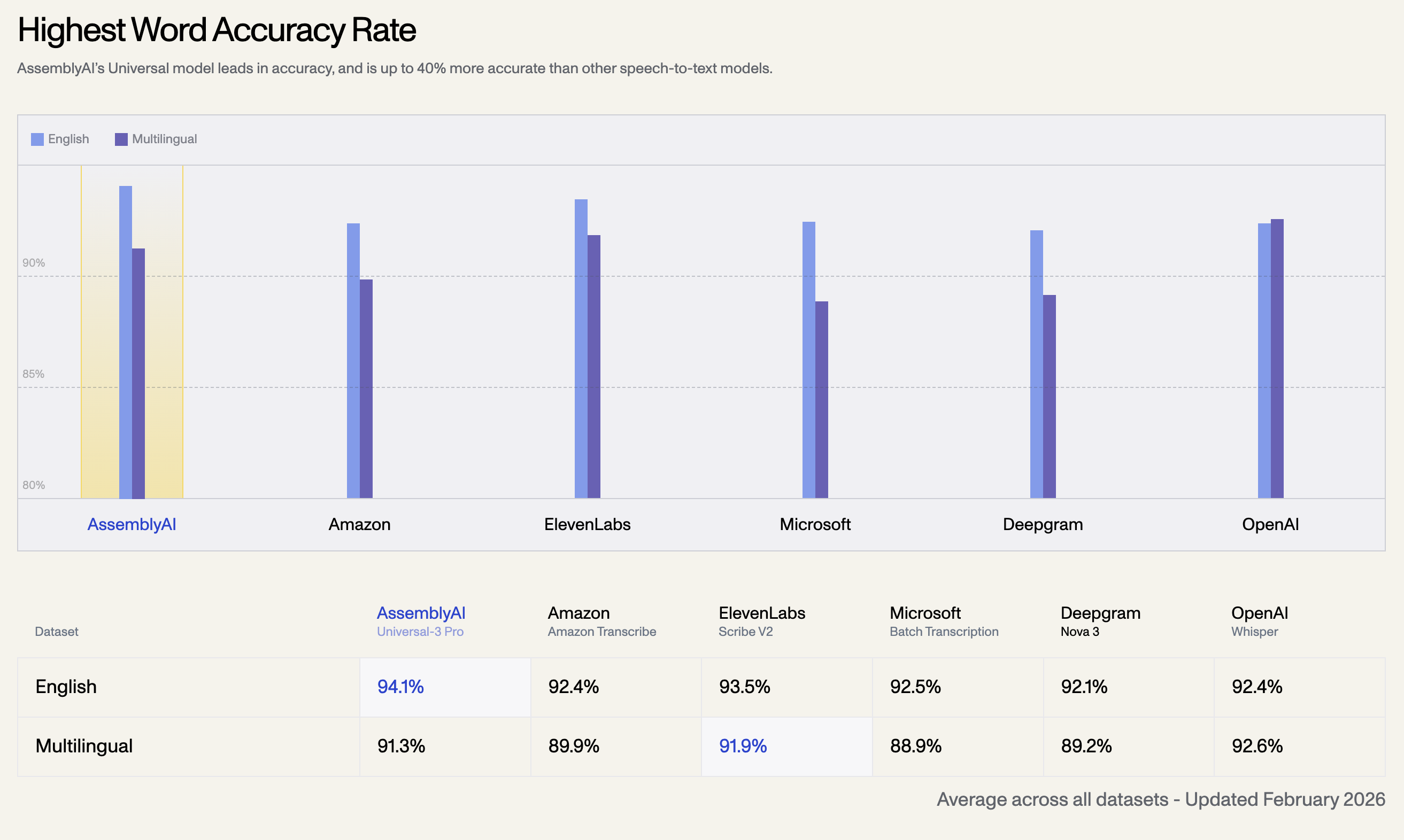
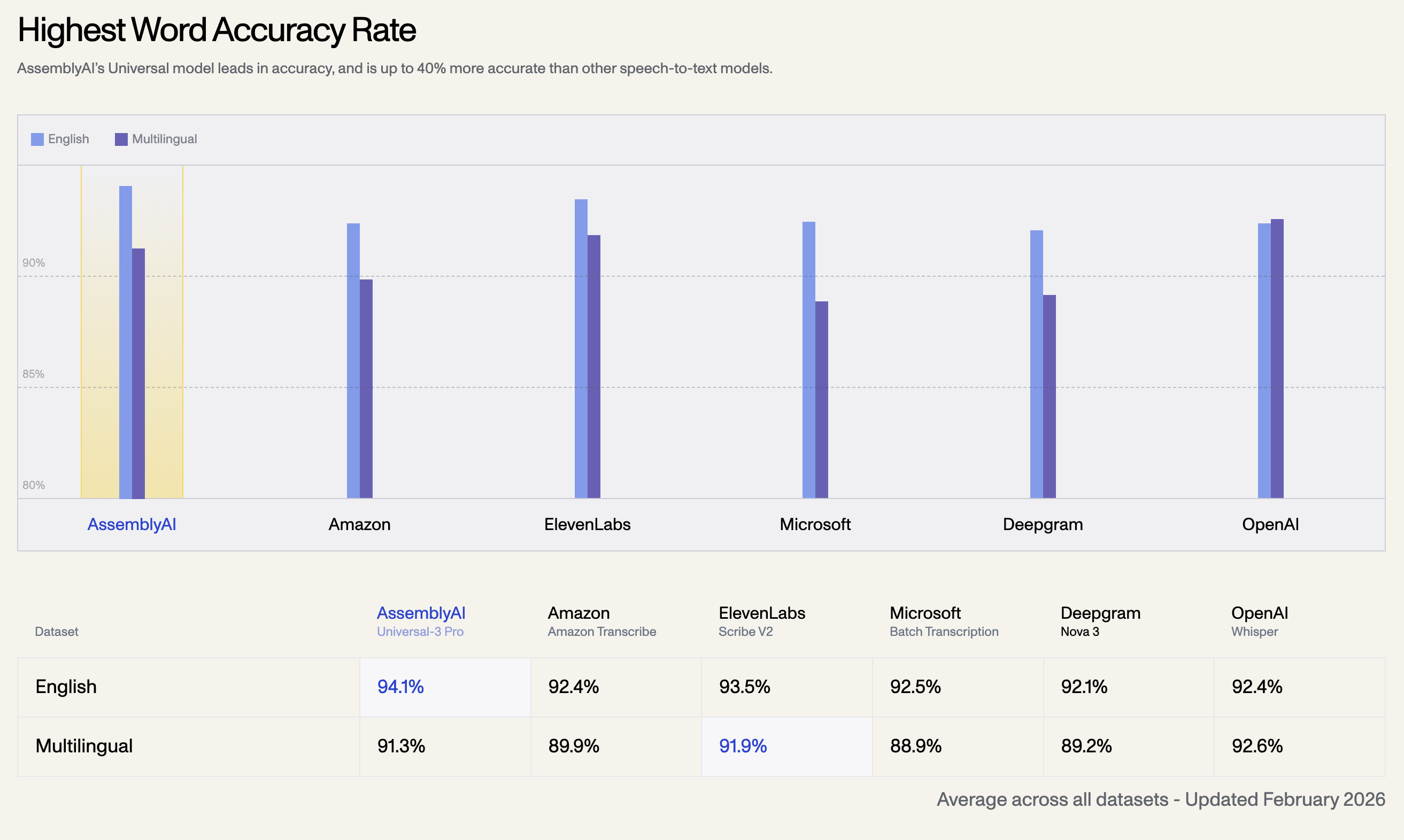
1. Taux de précision des mots le plus élevé
Le modèle Universal d'AssemblyAI est leader en matière de précision, et est jusqu'à 40 % plus précis que les autres modèles de reconnaissance vocale. Vous trouverez ci-dessous le taux de précision moyen sur tous les ensembles de données, mis à jour en février 2026 :
| Ensemble de données linguistiques | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Anglais | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Multilingue | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Taux d'erreur de mots (WER) le plus bas
Moins d'erreurs est essentiel pour construire des applications d'IA réussies autour des données vocales, y compris les résumés, les informations sur les clients, le marquage des métadonnées, les éléments d'action, et plus encore.
| Ensemble de données linguistiques | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| Anglais | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Multilingue | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Taux d'erreur de mots détaillé en anglais par ensemble de données
| Ensemble de données | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Noisy | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Broadcast (internal) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Earnings 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Moyenne | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. Types d'erreurs consécutives et réductions des hallucinations
Universal montre une réduction de 30 % des taux d'hallucinations par rapport à Whisper Large-v3. Nous définissons les hallucinations comme cinq insertions, substitutions ou suppressions consécutives ou plus par heure audio.
| Métrique d'erreur consécutive (Anglais) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabrications | 6.6% | 7.9% |
| Omissions | 5.3% | 5.5% |
| Hallucinations | 7.3% | 7.8% |
Comparaison des hallucinations en situation réelle
| Vérité terrain | AssemblyAI Universal-3 Pro | OpenAI Whisper (Hallucination) |
|---|---|---|
| her jewelry shimmered | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| the englishman said nothing | the englishman said nothing | does that mean we should not have interessant n |
| not in a month of sundays | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Comparaison fonctionnalité par fonctionnalité
Exécuter Whisper vous-même signifie gérer le GPU, la file d'attente, la fiabilité et la feuille de route. Comparez le modèle et l'API gérée d'AssemblyAI, leaders du secteur, par rapport aux principaux benchmarks de l'industrie.
| Fonctionnalité | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Taux de précision des mots | 94.1% | 92.4% |
| Taux d'erreur de mots CommonVoice (Anglais) | 4.13% | 8.52% |
| Taux d'erreur de mots sur données bruyantes (Anglais) | 9.97% | 11.63% |
| Diarisation des locuteurs | ✔ Oui (Intégré) | ❌ |
| Masquage des PII | ✔ Oui (Intégré) | ❌ |
| Résumé | ✔ Oui (Intégré) | ❌ |
| Analyse des sentiments | ✔ Oui (Intégré) | ❌ |
| Reconnaissance vocale en temps réel (Streaming) | ✔ Oui (Intégré) | Pas de capacités natives |
Pourquoi SRTGen alimente son générateur de sous-titres avec Universal-3 Pro
Lorsque nous avons conçu l'Espace de travail de sous-titres SRTGen, notre objectif était d'offrir aux éditeurs professionnels, aux créateurs de contenu généré par les utilisateurs (UGC) et aux entreprises l'outil de sous-titrage le plus rapide et le plus précis disponible. Bien que Whisper soit open-source, la gestion de clusters GPU Whisper personnalisés à grande échelle est coûteuse, et le simple transfert de texte brut ne nous offre pas l'alignement précis au niveau du mot ni la segmentation des locuteurs nécessaires pour des sous-titres de qualité professionnelle.
- Alignement mot par mot impeccable : Pour nos animations premium de type karaoké, nous devons savoir exactement quand chaque syllabe est prononcée. Universal-3 Pro offre une précision d'horodatage où la grande majorité des mots sont alignés à moins de 200 ms de leur fenêtre de parole réelle.
- Identification instantanée des locuteurs : Si votre vidéo contient une interview, un podcast ou plusieurs acteurs, notre espace de travail segmente automatiquement le dialogue par locuteur, vous permettant de coder par couleur et de regrouper les cartes de sous-titres de manière fluide.
- Latence d'infrastructure nulle : Nous gérons les ressources informatiques. Lorsque vous téléchargez une vidéo sur notre tableau de bord, nous nous occupons instantanément de l'extraction audio et de la transcription API parallèle, vous offrant un brouillon de sous-titres complet en moins d'une minute sans consommer vos ressources CPU ou GPU.
Conclusion : Choisir le bon moteur
Si vous avez des exigences strictes en matière d'auto-hébergement, d'opérations hors ligne ou si vous opérez à une échelle où l'exécution de GPU bruts est plus rentable, l'auto-hébergement de Whisper d'OpenAI est une voie solide.
Cependant, si votre priorité est la **précision immédiate, un formatage alphanumérique robuste, des horodatages clairs et l'identification intégrée des locuteurs**, l'intelligence gérée d'**Universal-3 Pro** est le vainqueur incontestable. En utilisant Universal-3 Pro en arrière-plan, SRTGen combine une précision de premier ordre avec notre tableau de bord de stylisation leader de l'industrie, vous offrant le meilleur des deux mondes.
Découvrez par vous-même la précision d'Universal-3 Pro. Rendez-vous sur l'Espace de travail SRTGen pour commencer à transcrire et styliser vos vidéos dès aujourd'hui !
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



