Universal-3 Pro 대 Whisper: 어떤 음성-텍스트 변환 모델이 더 나은가요?

Universal-3 Pro 대 Whisper: 어떤 음성-텍스트 변환 모델이 더 나은가요?
자동 음성 인식(ASR)은 거대한 패러다임 변화를 겪었습니다. 딥러닝 기반 음성 모델의 등장은 원본 전사 정확도를 인간 수준에 그 어느 때보다 가깝게 만들었습니다. 미디어 현지화 도구, 비디오 자막 편집기, 음성 분석 스위트를 구축하는 개발자에게 올바른 백엔드 모델을 선택하는 것은 사용자 경험과 계산 비용에 직접적인 영향을 미치는 중요한 결정입니다.
오늘날 음성-텍스트 변환 분야의 두 거물은 OpenAI의 Whisper(특히 Whisper large-v3)와 AssemblyAI의 Universal-3 Pro입니다. Whisper는 기본 오픈소스 솔루션으로 자리 잡았지만, Universal-3 Pro는 선도적인 엔터프라이즈급 관리형 대안으로 자리매김했습니다.
SRTGen에서는 전문가용 자막 작업 공간을 위해 두 모델을 광범위하게 평가했습니다. 오늘 저희는 벤치마크 분석 결과를 공유하고, 궁극적으로 AssemblyAI Universal-3 Pro를 중심으로 작업 공간을 구축한 이유를 설명하며, 두 모델이 정확도, 환각 현상, 형식, 기능 세트 전반에서 어떻게 비교되는지 분석할 것입니다.
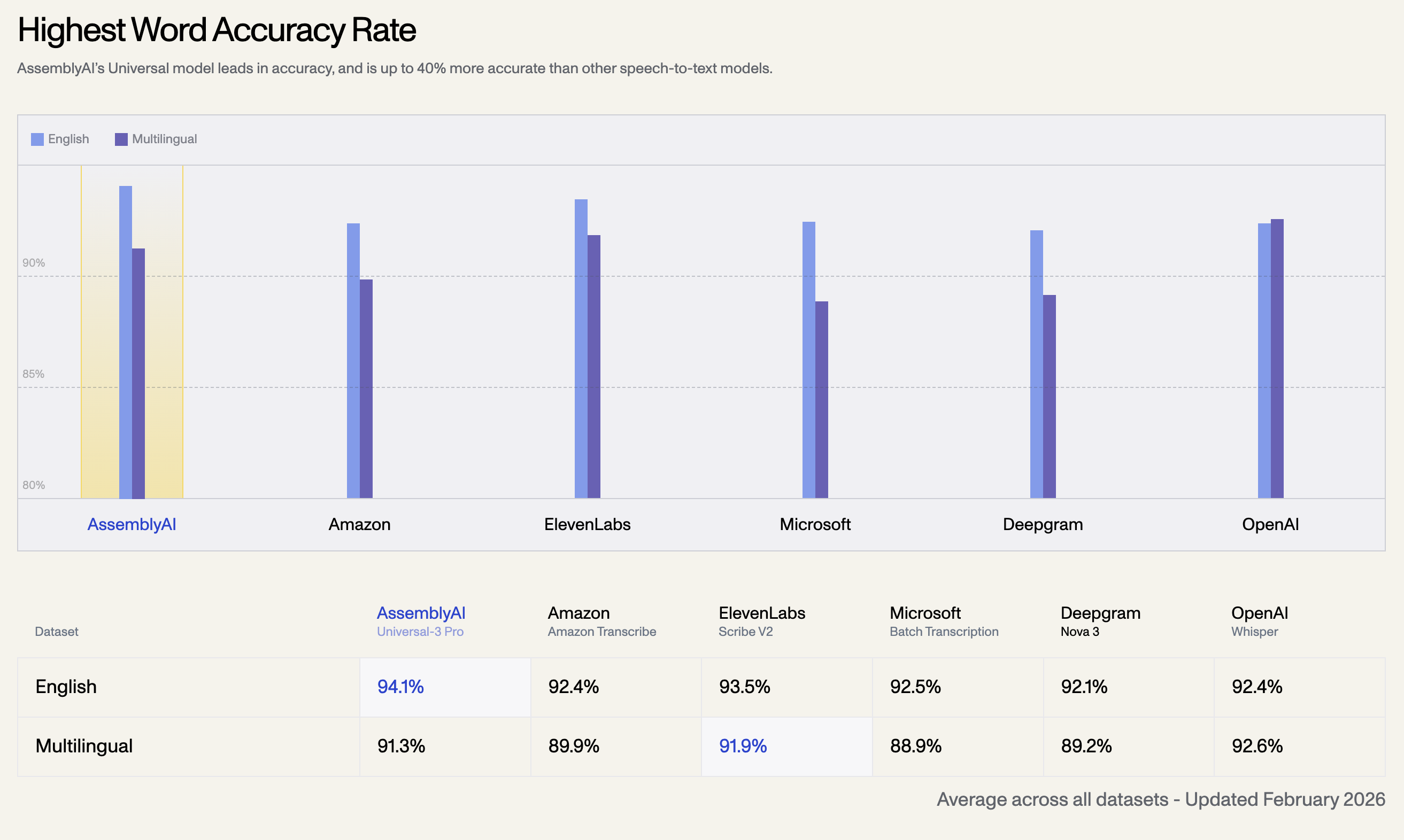
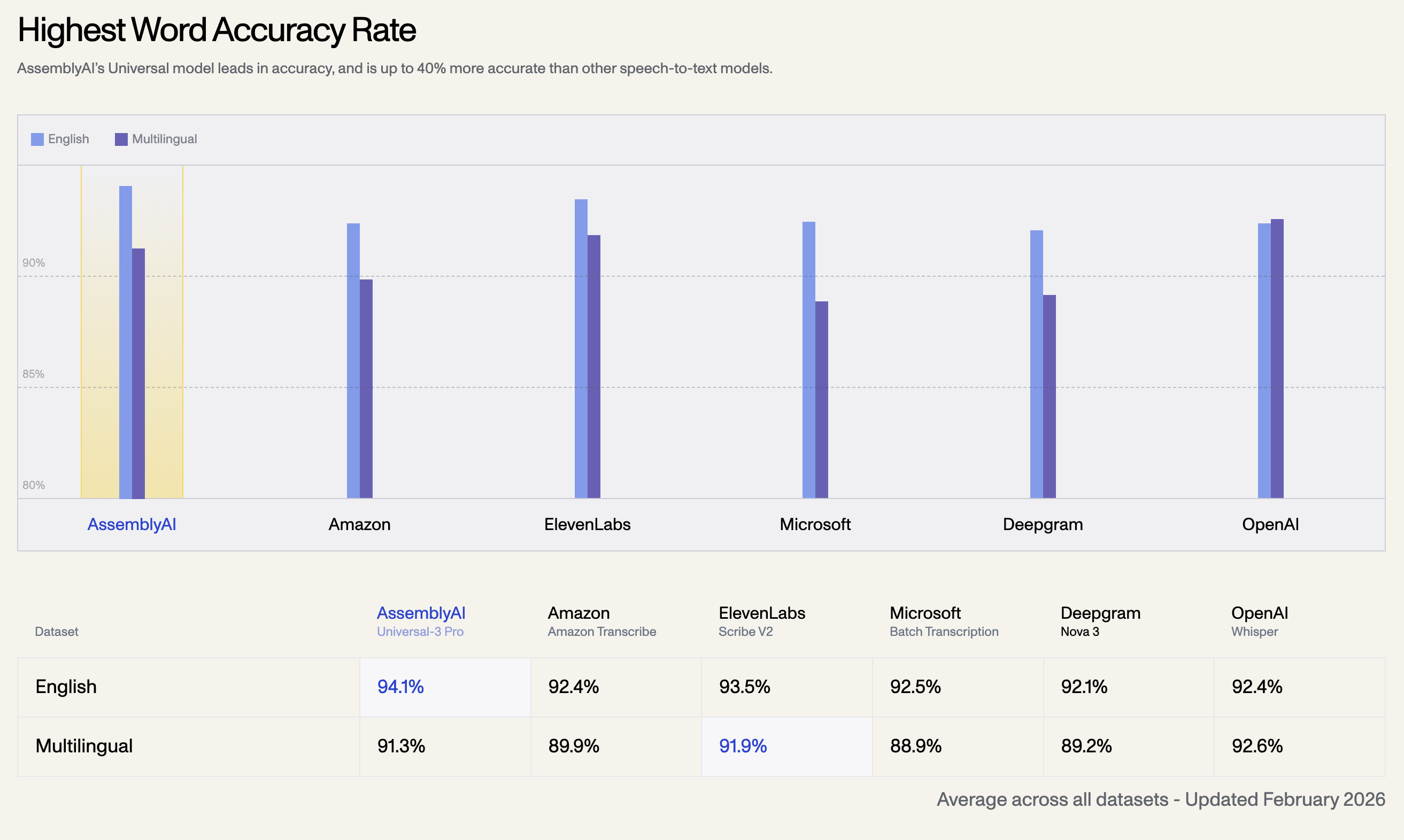
1. 최고 단어 정확도
AssemblyAI의 Universal 모델은 정확도에서 선두를 달리며, 다른 음성-텍스트 변환 모델보다 최대 40% 더 정확합니다. 아래는 2026년 2월에 업데이트된 모든 데이터셋에 대한 평균 정확도입니다.
| 언어 데이터셋 | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| 영어 | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| 다국어 | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. 최저 단어 오류율 (WER)
요약, 고객 통찰력, 메타데이터 태깅, 실행 항목 등 음성 데이터를 기반으로 성공적인 AI 애플리케이션을 구축하는 데 오류 감소는 매우 중요합니다.
| 언어 데이터셋 | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| 영어 | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| 다국어 | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. 데이터셋별 영어 단어 오류율 상세 분석
| 데이터셋 | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| 노이즈 | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| 팟캐스트 | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| 방송 (내부) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| 수익 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| 웹 세미나 | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| 평균 | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. 연속 오류 유형 및 환각 현상 감소
Universal은 Whisper Large-v3에 비해 환각 현상 발생률이 30% 감소했습니다. 저희는 환각 현상을 오디오 시간당 5개 이상의 연속적인 삽입, 대체 또는 삭제로 정의합니다.
| 연속 오류 지표 (영어) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| 조작 | 6.6% | 7.9% |
| 누락 | 5.3% | 5.5% |
| 환각 | 7.3% | 7.8% |
실제 환각 현상 비교
| 원본 텍스트 | AssemblyAI Universal-3 Pro | OpenAI Whisper (환각 현상) |
|---|---|---|
| 그녀의 보석이 반짝였다 | 그녀의 보석이 반짝였다 | hadja luis sima addjilu sime subtitles by the amara org community |
| 태백산맥은 종종 한반도의 등뼈로 여겨진다 | 태백산맥은 종종 한반도의 등뼈로 여겨진다 | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| 그 영국인은 아무 말도 하지 않았다 | 그 영국인은 아무 말도 하지 않았다 | does that mean we should not have interessant n |
| 절대로 | 절대로 | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. 기능별 비교
Whisper를 직접 운영한다는 것은 GPU, 큐, 안정성, 로드맵을 모두 관리해야 한다는 의미입니다. AssemblyAI의 업계 선도적인 모델과 관리형 API를 주요 산업 벤치마크에 따라 비교해 보세요.
| 기능 | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| 단어 정확도 | 94.1% | 92.4% |
| CommonVoice 단어 오류율 (영어) | 4.13% | 8.52% |
| 노이즈 단어 오류율 (영어) | 9.97% | 11.63% |
| 화자 분리 | ✔ 예 (내장) | ❌ |
| 개인 식별 정보(PII) 수정 | ✔ 예 (내장) | ❌ |
| 요약 | ✔ 예 (내장) | ❌ |
| 감성 분석 | ✔ 예 (내장) | ❌ |
| 스트리밍 음성-텍스트 변환 | ✔ 예 (내장) | 기본 기능 없음 |
SRTGen이 자막 생성기에 Universal-3 Pro를 사용하는 이유
SRTGen 자막 작업 공간을 설계할 때, 저희의 목표는 전문 편집자, UGC 제작자 및 기업에 가장 빠르고 정확한 자막 도구를 제공하는 것이었습니다. Whisper는 오픈소스이지만, 사용자 정의 Whisper GPU 클러스터를 대규모로 관리하는 것은 비용이 많이 들며, 원본 텍스트를 주고받는 방식으로는 전문가 수준의 캡션에 필요한 정확한 단어 수준 정렬 또는 화자 분할 기능을 제공하지 못합니다.
AssemblyAI Universal-3 Pro를 주 전사 엔진으로 선택함으로써, 저희는 몇 가지 주요 이점을 얻습니다.
- 완벽한 단어별 정렬: 프리미엄 노래방 스타일 애니메이션을 위해서는 모든 음절이 정확히 언제 발화되는지 알아야 합니다. Universal-3 Pro는 대부분의 단어가 실제 발화 시점으로부터 200ms 이내에 정렬되는 정밀한 타임스탬프를 제공합니다.
- 즉각적인 화자 레이블링: 비디오에 인터뷰, 팟캐스트 또는 여러 출연자가 등장하는 경우, 저희 작업 공간은 대화를 화자별로 자동으로 분할하여 자막 카드를 색상으로 구분하고 원활하게 그룹화할 수 있게 합니다.
- 제로 인프라 지연 시간: 저희가 컴퓨팅 리소스를 처리합니다. 대시보드에서 비디오를 업로드하면, 저희는 오디오 추출 및 병렬 API 전사를 즉시 처리하여 CPU 또는 GPU 리소스를 소모하지 않고 1분 이내에 완전한 자막 초안을 제공합니다.
결론: 올바른 엔진 선택
자체 호스팅, 오프라인 운영, 또는 원시 GPU를 실행하는 것이 더 비용 효율적인 규모로 운영해야 하는 엄격한 요구 사항이 있다면, OpenAI의 Whisper를 자체 호스팅하는 것이 확실한 방법입니다.
하지만 **즉각적인 정확성, 강력한 영숫자 형식 지정, 깔끔한 타임스탬프, 그리고 내장된 화자 레이블링**이 최우선이라면, **Universal-3 Pro**의 관리형 인텔리전스가 명확한 승자입니다. SRTGen은 Universal-3 Pro를 배경에서 활용함으로써 최고 수준의 정확성과 업계 선도적인 스타일링 대시보드를 결합하여 두 가지 장점을 모두 제공합니다.
Universal-3 Pro의 정밀함을 직접 경험해보세요. SRTGen 작업 공간으로 이동하여 지금 바로 비디오를 전사하고 스타일링을 시작하세요!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



