Universal-3 Pro vs Whisper: Which Speech-to-Text Model is Better?

Universal-3 Pro vs Whisper: Which Speech-to-Text Model is Better?
Automatic Speech Recognition (ASR) has undergone a massive paradigm shift. The arrival of deep-learning-based speech models has pushed raw transcription accuracy closer than ever to human parity. For developers building media localization tools, video caption editors, and speech analytics suites, choosing the right backend model is a critical decision that directly impacts user experience and computational costs.
Today, the two heavyweights of the Speech-to-Text landscape are OpenAI's Whisper (specifically Whisper large-v3) and AssemblyAI's Universal-3 Pro. While Whisper has become the default open-source darling, Universal-3 Pro has established itself as the leading enterprise-grade managed alternative.
At SRTGen, we evaluated both models extensively for our professional subtitle workspace. Today, we are sharing our benchmark analysis, explaining why we ultimately built our workspace around AssemblyAI Universal-3 Pro, and breaking down how both models stack up across accuracy, hallucinations, formatting, and feature sets.
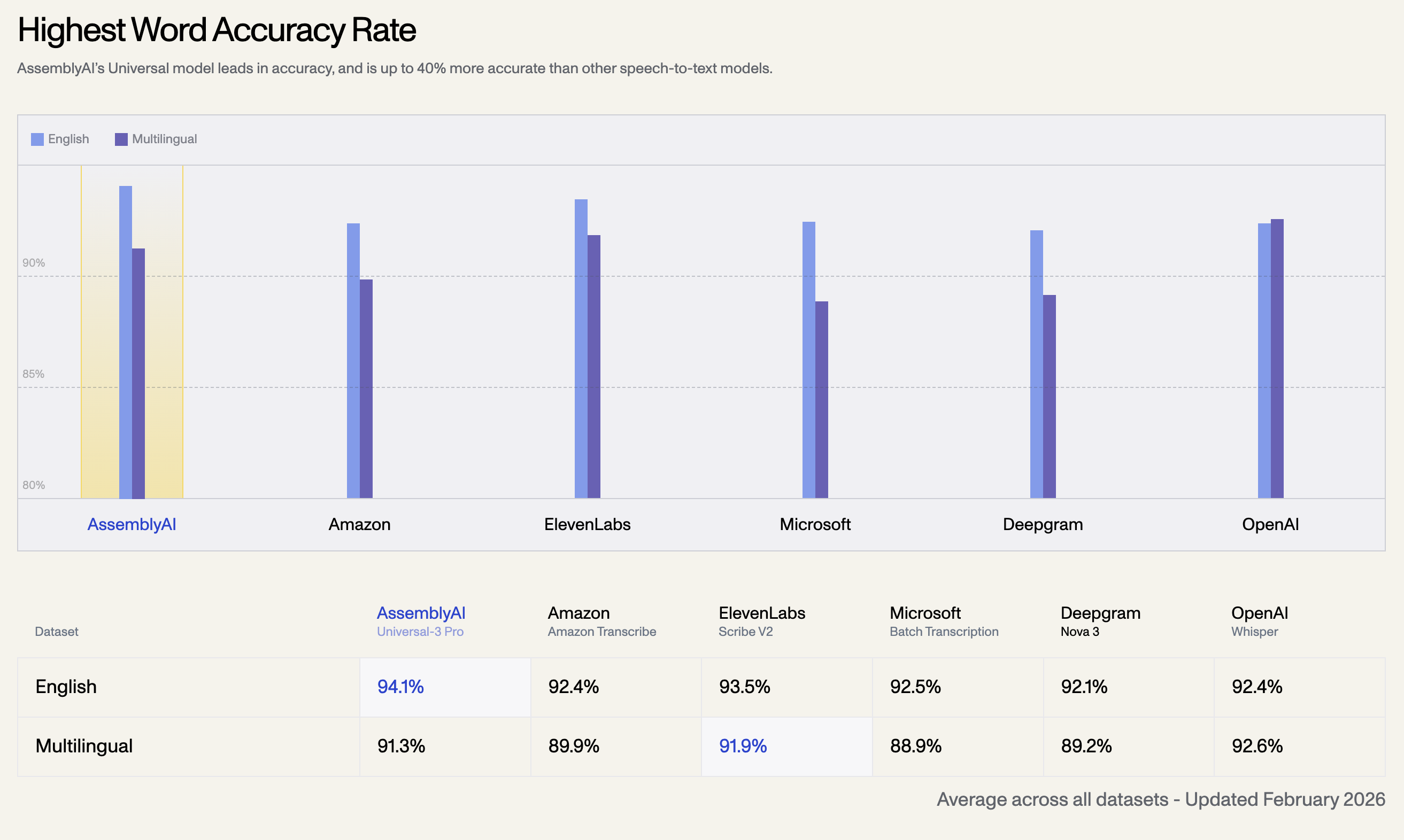
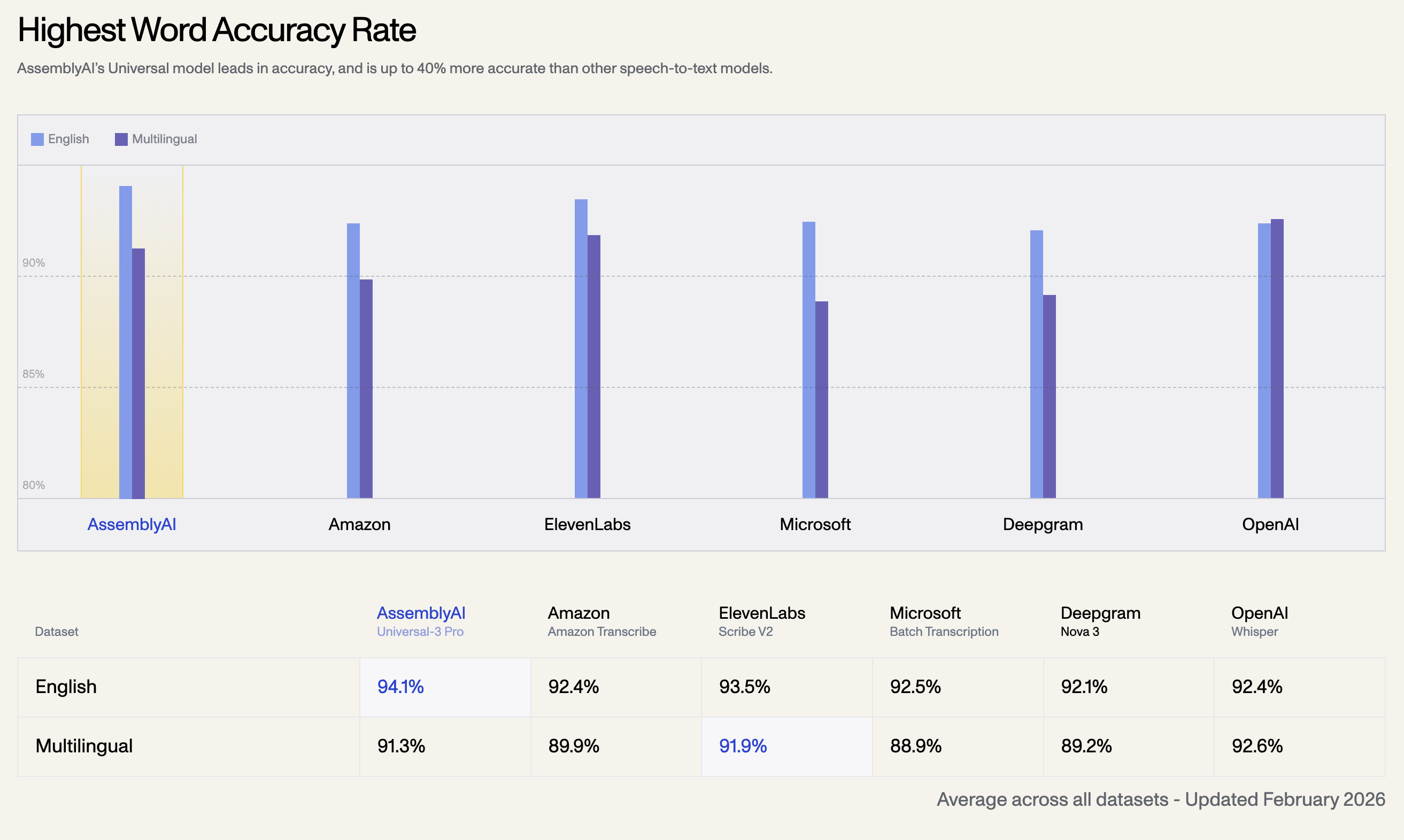
1. Highest Word Accuracy Rate
AssemblyAI’s Universal model leads in accuracy, and is up to 40% more accurate than other speech-to-text models. Below is the average accuracy rate across all datasets, updated in February 2026:
| Language Dataset | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| English | 94.1% | 92.4% | 93.5% | 92.5% | 92.1% | 92.4% |
| Multilingual | 91.3% | 92.6% | 91.9% | 89.9% | 88.9% | 89.2% |
2. Lowest Word Error Rate (WER)
Fewer errors are critical to building successful AI applications around voice data—including summaries, customer insights, metadata tagging, action items, and more.
| Language Dataset | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| English | 5.9% | 6.5% | 6.5% | 7.6% | 7.5% | 8.1% |
| Multilingual | 8.7% | 7.4% | 8.1% | 10.1% | 11.1% | 10.8% |
3. Detailed English Word Error Rate per Dataset
| Dataset | AssemblyAI Universal-3 Pro | OpenAI Whisper | ElevenLabs Scribe V2 | Amazon Transcribe | Microsoft Batch | Deepgram Nova 3 |
|---|---|---|---|---|---|---|
| CommonVoice | 4.13% | 8.52% | 5.38% | 5.16% | 7.76% | 10.45% |
| Noisy | 9.97% | 11.63% | 13.72% | 24.73% | 14.26% | 14.12% |
| Podcast | 6.65% | 10.32% | 10.90% | 11.23% | 11.37% | 10.23% |
| Tedlium | 7.22% | 8.70% | 6.03% | 6.18% | 6.60% | 6.36% |
| Rev16 | 7.93% | 11.61% | 10.08% | 11.30% | 11.23% | 10.81% |
| LibriSpeech Clean | 1.46% | 2.28% | 2.17% | 2.05% | 2.32% | 2.56% |
| LibriSpeech Test-Other | 2.56% | 4.64% | 3.05% | 4.30% | 5.07% | 5.48% |
| Broadcast (internal) | 4.24% | 4.75% | 7.30% | 5.33% | 6.06% | 5.85% |
| Earnings 2021 | 9.70% | 9.87% | 6.61% | 8.37% | 7.82% | 11.38% |
| Webinar | 5.51% | 6.99% | 9.78% | 10.12% | 10.07% | 9.54% |
| Average | 5.72% | 7.45% | 7.08% | 8.14% | 8.14% | 8.38% |
4. consecutive Error Types & Hallucination Reductions
Universal shows a 30% reduction in hallucination rates compared to Whisper Large-v3. We define hallucinations as five or more consecutive insertions, substitutions, or deletions per audio hour.
| Consecutive Error Metric (English) | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Fabrications | 6.6% | 7.9% |
| Omissions | 5.3% | 5.5% |
| Hallucinations | 7.3% | 7.8% |
Real-World Hallucination Comparison
| Ground-truth | AssemblyAI Universal-3 Pro | OpenAI Whisper (Hallucination) |
|---|---|---|
| her jewelry shimmered | her jewelry shimmering | hadja luis sima addjilu sime subtitles by the amara org community |
| the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the Taebaek mountain chain is often considered the backbone of the Korean Peninsula | the ride to price inte i daseline is about 3 feet tall and suites sizes is 하루 |
| the englishman said nothing | the englishman said nothing | does that mean we should not have interessant n |
| not in a month of sundays | not in a month of sundays | this time i am very happy and then thank you to my co workers get them back to jack corn again thank you to all of you who supported me the job you gave me ultimately gave me nothing however i thank all of you for supporting me thank you to everyone at jack corn thank you to michael john song trabalhar significant |
5. Feature-by-Feature Comparison
Running Whisper yourself means owning the GPU, the queue, the reliability, and the roadmap. Compare AssemblyAI's industry-leading model and managed API across major industry benchmarks.
| Feature | AssemblyAI Universal-3 Pro | OpenAI Whisper |
|---|---|---|
| Word Accuracy Rate | 94.1% | 92.4% |
| CommonVoice Word Error Rate (English) | 4.13% | 8.52% |
| Noisy Word Error Rate (English) | 9.97% | 11.63% |
| Speaker Diarization | ✔ Yes (Built-in) | ❌ |
| PII Redaction | ✔ Yes (Built-in) | ❌ |
| Summarization | ✔ Yes (Built-in) | ❌ |
| Sentiment Analysis | ✔ Yes (Built-in) | ❌ |
| Streaming Speech-to-Text | ✔ Yes (Built-in) | No native capabilities |
Why SRTGen Powers Its Subtitle Generator with Universal-3 Pro
When we designed the SRTGen Subtitle Workspace, our goal was to offer professional editors, UGC creators, and businesses the fastest and most accurate subtitling tool available. While Whisper is open-source, managing custom Whisper GPU clusters at scale is expensive, and passing raw text back and forth doesn't give us the precise word-level alignment or speaker segmentation required for professional-grade captions.
By selecting AssemblyAI Universal-3 Pro as our primary transcription engine, we gain several key advantages:
- Flawless Word-by-Word Alignment: For our premium karaoke-style animations, we need to know exactly when every single syllable is spoken. Universal-3 Pro delivers timestamp precision where the vast majority of words are aligned within 200ms of their actual speech window.
- Instant Speaker Labeling: If your video features an interview, a podcast, or multiple actors, our workspace automatically segments the dialogue by speaker, letting you color-code and group subtitle cards seamlessly.
- Zero Infrastructure Latency: We handle the computing resources. When you upload a video in our dashboard, we handle audio extraction and parallel API transcription instantly, giving you a complete subtitle draft in under a minute without consuming your CPU or GPU resources.
Conclusion: Choosing the Right Engine
If you have strict requirements for self-hosting, offline operations, or are operating on a scale where running raw GPUs is more cost-effective, self-hosting OpenAI's Whisper is a solid path.
However, if your priority is **immediate accuracy, robust alphanumeric formatting, clean timestamps, and built-in speaker labeling**, the managed intelligence of **Universal-3 Pro** is the clear winner. By utilizing Universal-3 Pro behind the scenes, SRTGen combines top-tier accuracy with our industry-leading styling dashboard, providing you with the best of both worlds.
Experience the precision of Universal-3 Pro yourself. Head to the SRTGen Workspace to start transcribing and styling your videos today!
David Lin
Founder, SRTGen
Video creator and developer focused on building professional automation tools.



